
Agent Memory Systems and Knowledge Graphs: Letta, Mem0, Graphiti, and Cognee
Design · A close look at four approaches to long-term agent memory, from text blocks to temporal graphs

Four popular agent-memory libraries each pick a different answer to the same design question. How should an agent remember things across sessions? Letta edits plain text blocks and files. Mem0 keeps a vector store with entity hints. Graphiti indexes facts as time-stamped relationships. Cognee runs an entity extraction pipeline.
Knowledge graphs store facts as typed relationships between entities. Obsidian built a million-user product on bidirectional note links navigable as a graph. Karpathy’s LLM Wiki proposed having an LLM build a persistent knowledge base from scratch. Graph structure could let you traverse connections across facts rather than just match by similarity. But a growing number of practitioners argue files alone work well enough in practice, and specialized graph tooling adds complexity without proportional benefit. We line the four up from least graph to most and trace two concerns through each one. Do related facts get pulled back together, and how do fact changes get handled?
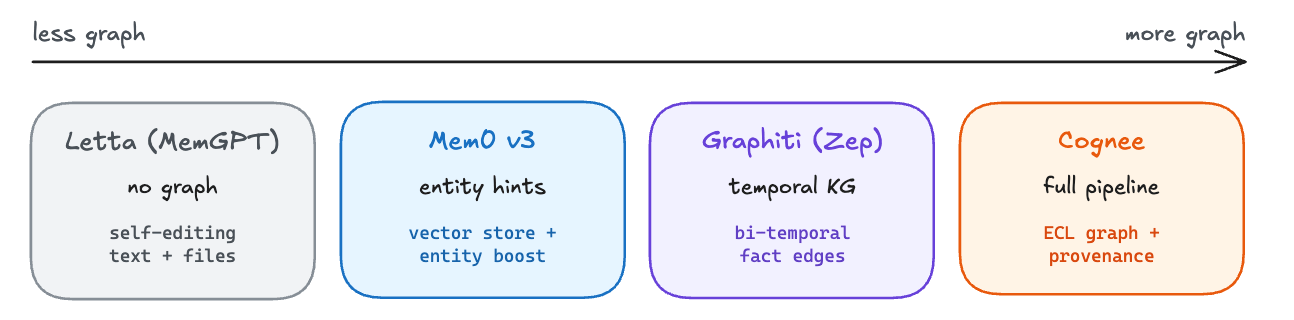
Letta is a full agent framework that runs the agent for you. Mem0, Graphiti, and Cognee are memory layers you bolt onto your own agent. All four run paid cloud services on top of their OSS (Letta Inc., Mem0 Inc., Zep, Topoteretes), each with features beyond the OSS. This post covers the open-source versions.
Letta (MemGPT): self-editing text blocks
Letta uses no graph. Memory is split into tiers the agent manages itself. Memory blocks stay in context permanently. Each is a labeled text field with a fixed character limit the LLM reads and edits on every turn. Outside that sit archival memory searched by vector on demand, the recall message history, and an optional filesystem surface for uploaded docs.
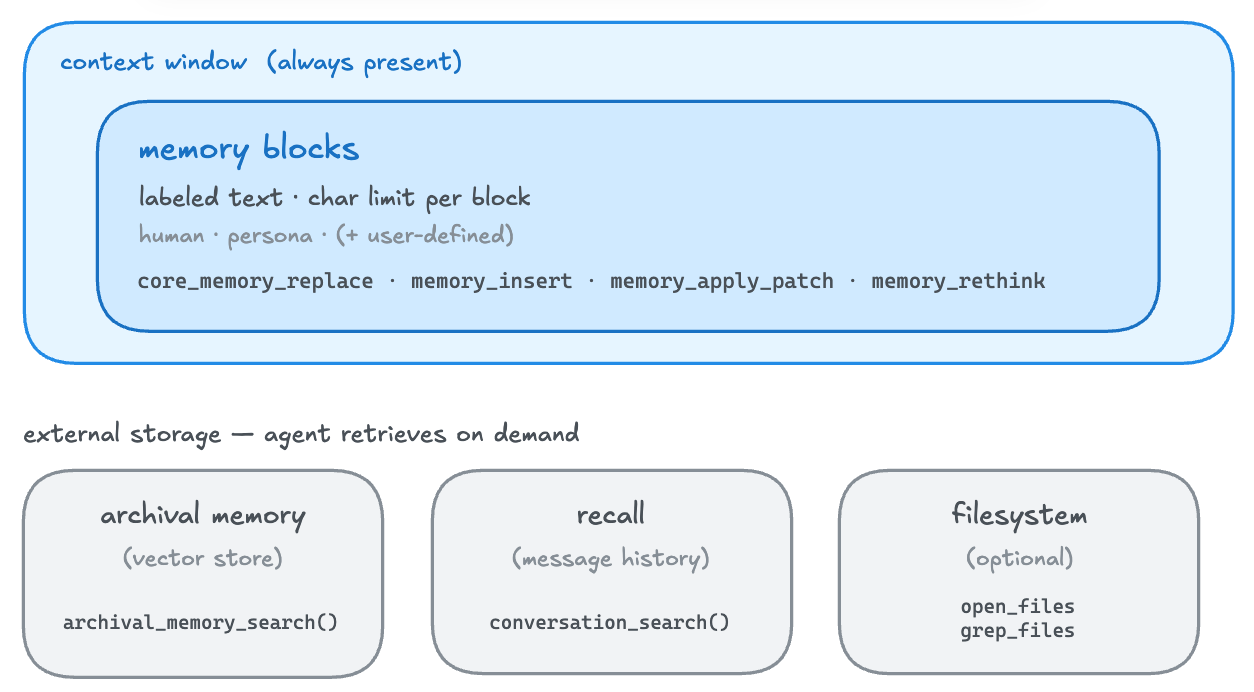
The agent edits its own memory with tool calls. The edit surface is a handful of functions: core_memory_replace, memory_replace, memory_insert, memory_apply_patch, and memory_rethink. Retrieval is agent-driven too, through archival_memory_search and conversation_search plus filesystem open_files and grep_files.
core_memory_replace is the simplest of those edit-surface functions.
functions/function_sets/base.py:263-280
def core_memory_replace(agent_state, label, old_content, new_content) -> str:
"""Replace the contents of core memory. To delete memories, use an empty string for new_content."""
current_value = str(agent_state.memory.get_block(label).value)
new_value = current_value.replace(str(old_content), str(new_content))
agent_state.memory.update_block_value(label=label, value=new_value)
return new_valueThe update is a plain string swap on block text, with no structure tracking what changed or when. Whether an outdated fact gets replaced depends entirely on the LLM noticing the contradiction and calling the function. Letta also ships sleeptime agents (letta/groups/sleeptime_multi_agent_v*.py), a background loop that consolidates and rewrites blocks between turns, so memory can change outside a live interaction. The mechanism is still self-editing text.
To walk through the full flow end to end, say you give the agent a human block that reads “Lives in Boston.” You send “I moved from Boston to SF.” The agent reads its own block, sees the contradiction, and calls core_memory_replace to swap “Boston” for “SF” in the text. When you later ask “Where do I live?”, there is no retrieval step because that block is always in context and now reads “Lives in SF.” Boston is gone with no record it was ever there. The flow hangs on the model noticing the contradiction and choosing to overwrite. Nothing fires if it does not.
Letta’s “Is a Filesystem All You Need?” post (Aug 2025) dumped LOCOMO (a multi-session dialogue recall benchmark) conversation transcripts into files attached to a plain agent and scored 74.0%, above the 68.5% for Mem0’s graph variant (arXiv 2504.19413, Apr 2025). Letta argues that agents are post-trained to be good at iterative file search, so specialized memory systems add little.
Mem0: graph out, entity linking in
Mem0 started with an optional graph layer and then removed it from the v3 open-source rewrite. That deletion is OSS-only. Mem0’s hosted Platform still lists graph memory and time-based decay as features.
Graph memory arrived in PR #1718 as an opt-in layer, then grew through 2025 to store that graph in any of five graph databases, Neo4j, the in-memory Memgraph, the embedded Kuzu, AWS’s managed Amazon Neptune, and Apache AGE, a graph extension for Postgres. The v3 pipeline removed the module in commit a488e190 (PR #4805, merged Apr 14 2026).
Entity linking replaced graph memory. Entities are pulled out with spaCy rather than an LLM and stored in a parallel {collection}_entities vector collection. Each entity row holds a linked_memory_ids list. That is a hub-and-spoke structure, an entity pointing back at memories that mention it, not typed edges. At query time, entity overlap becomes one signal in an additive score, semantic plus BM25 plus an entity boost, fused and normalized.
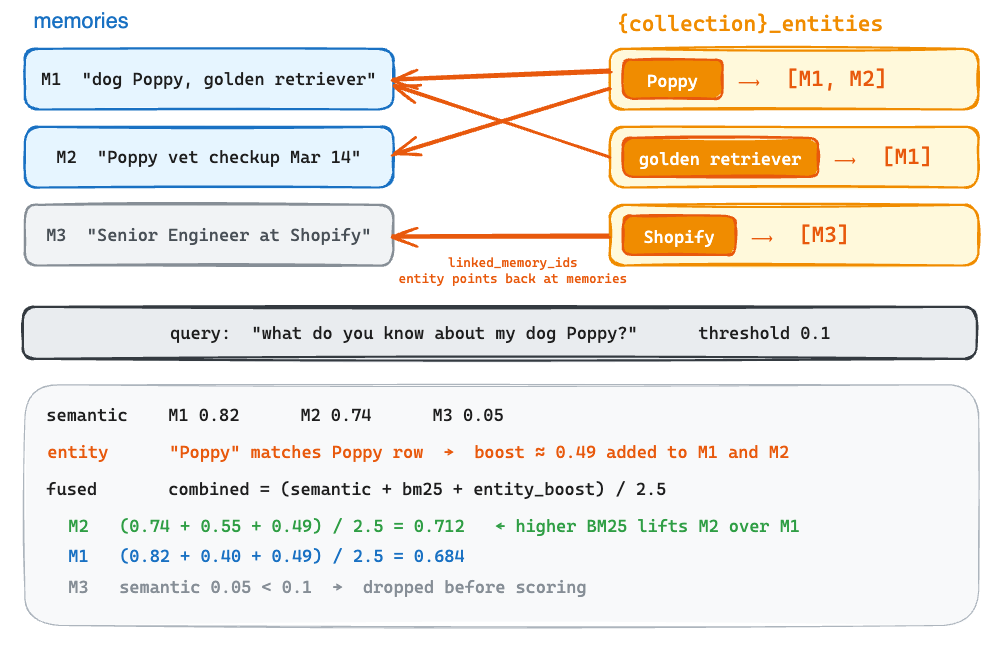
The entity boost computation is three lines of arithmetic.
num_linked = max(len(linked_memory_ids), 1)
memory_count_weight = 1.0 / (1.0 + 0.001 * ((num_linked - 1) ** 2))
boost = similarity * ENTITY_BOOST_WEIGHT * memory_count_weightAn entity match boosts every memory it links to, attenuated by memory_count_weight so a ubiquitous entity does not flood results. Relationship awareness is a number added to a vector score.
In the Poppy example, M1 and M2 both clear the 0.1 threshold and come back as the retrieved pair, with M3 dropped. The “Poppy” boost is identical on both, so it does not set their order. M2 edges ahead on the BM25 keyword term (BM25 scores literal word overlap with the query, unlike the embedding-based semantic score), which outweighs M1’s higher semantic score. What comes back is the raw memory text, which the agent drops into its prompt and answers from. Mem0 gave up structural typed traversal, the ability to answer “who owns the dog that had the checkup” by walking edges. It kept the cheap win, co-retrieving memories that share an entity.
Why drop the graph? Mem0’s own paper (arXiv 2504.19413, April 2025) benchmarked the graph variant Mem0g against the plain vector Mem0 on LOCOMO and the graph rarely justified its cost.
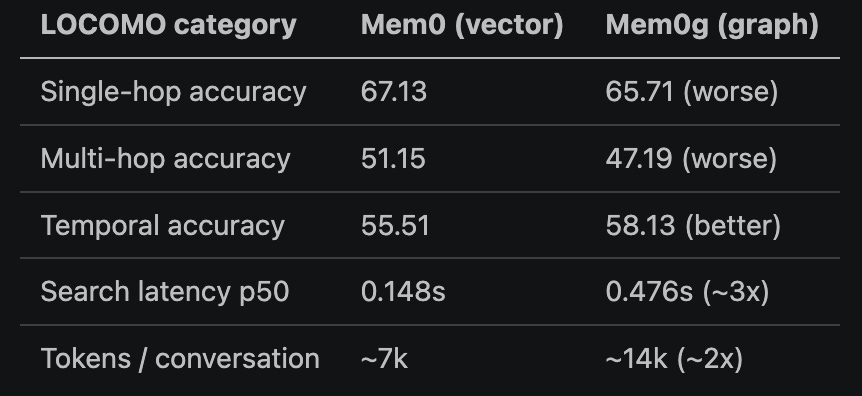
The graph variant edged ahead on the overall score, 68.44 to 66.88, and won temporal, but the gain stayed thin. It lost single-hop and multi-hop, ran search about 3x slower, and cost about 2x the tokens.
Graphiti (Zep): bi-temporal fact graph
Graphiti is built entirely around the graph. The data model has EpisodicNodes that store the original input each fact was extracted from, EntityNodes, CommunityNodes that summarize clusters of related entities, and an EntityEdge that is the fact edge, Entity --RELATES_TO--> Entity, with fact text and embedding.
Every fact edge is bi-temporal. It records valid time, when the fact was true in the world (valid_at/invalid_at), and transaction time, when the system knew it (created_at/expired_at).
graphiti_core/edges.py:271-279
expired_at: datetime | None = Field(default=None, description='datetime of when the node was invalidated') # transaction time
valid_at: datetime | None = Field(default=None, description='datetime of when the fact became true') # valid time
invalid_at: datetime | None = Field(default=None, description='datetime of when the fact stopped being true') # valid timeWhen a contradicting fact arrives, the old edge is stamped invalid rather than deleted.
graphiti_core/utils/maintenance/edge_operations.py:569-571
edge.invalid_at = resolved_edge.valid_at
edge.expired_at = edge.expired_at if edge.expired_at is not None else utc_now()
invalidated_edges.append(edge)Graphiti closes the old edge instead of deleting it. The old fact stays queryable, so you can ask what is true now versus what was true then.
Ingestion is incremental. Each call to add_episode triggers LLM extraction of nodes and edges, entity resolution with a deterministic MinHash and LSH fast path plus an LLM fallback, then edge dedup and contradiction resolution. There is no batch recompute, unlike static GraphRAG. Retrieval combines cosine similarity, BM25, and breadth-first graph traversal, with pluggable rerankers (RRF, node-distance, MMR, episode-mentions, cross-encoder), and skips LLM summarization at query time to keep latency sub-second.
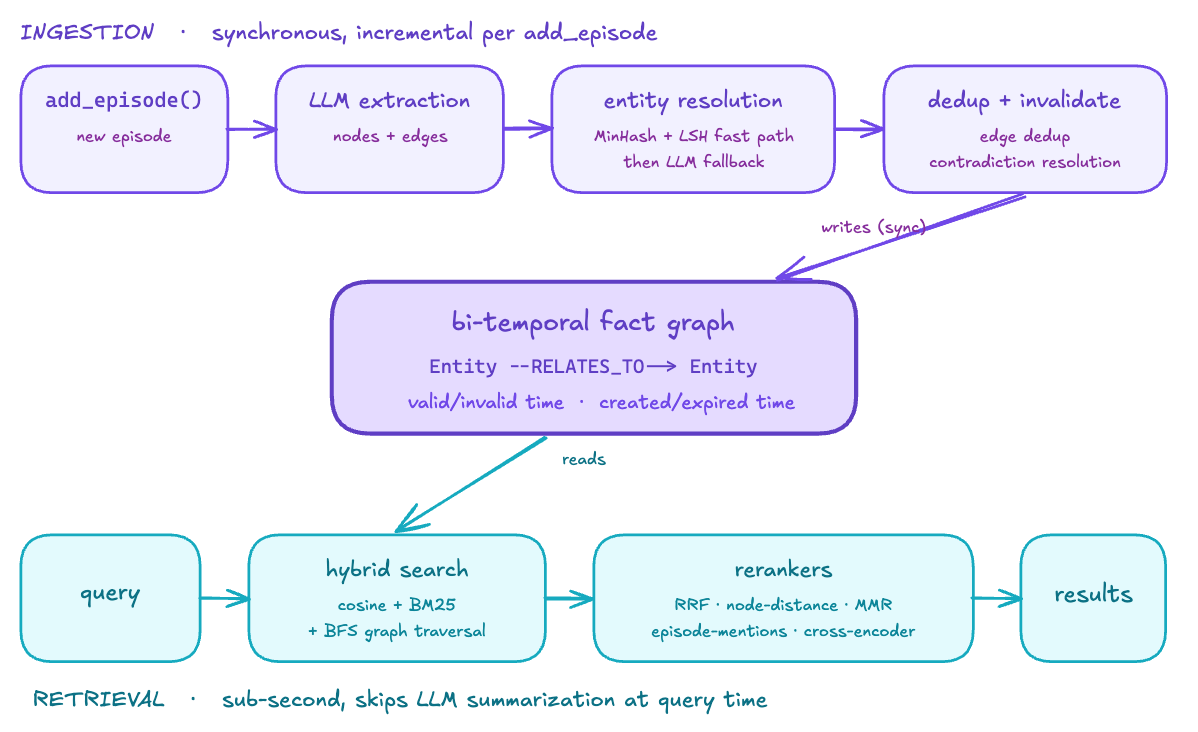
The cost is high. A single episode can fire many LLM calls, node extraction then dedup then edge extraction then per-edge resolution, timestamping, and attributes. This is the expensive end of the spectrum, the inverse of Mem0’s bet. The Zep paper (arXiv 2501.13956) and README carry the upside claims.
Cognee: extract, cognify, load
Cognee treats memory as a data-engineering problem. Its pipeline is an ECL, Extract then Cognify then Load. The public API is add(), cognify(), search(), and memify(), with a newer agent facade of remember/recall/forget/improve.
cognee/api/v1/cognify/cognify.py:316-344
default_tasks = [
# EXTRACT: classify raw Data items into typed Document objects
Task(classify_documents),
# EXTRACT: split Documents into semantic text chunks
Task(
extract_chunks_from_documents,
max_chunk_size=chunk_size or get_max_chunk_tokens(),
chunker=chunker,
),
# COGNIFY: LLM-extract entities and relationships into a knowledge graph
# COGNIFY: LLM-summarize each chunk for retrieval
Task(
extract_graph_and_summarize,
graph_model=graph_model,
config=config,
custom_prompt=custom_prompt,
task_config={"batch_size": chunks_per_batch},
**kwargs,
),
# LOAD: persist nodes, edges, and embeddings to graph/vector DBs
Task(
add_data_points,
embed_triplets=embed_triplets,
task_config={"batch_size": chunks_per_batch},
),
Task(extract_dlt_fk_edges),
]The DataPoint ontology declares graph edges as typed Pydantic fields that point at other DataPoints.
cognee/modules/chunking/models/DocumentChunk.py:10-37
class DocumentChunk(DataPoint):
text: str
chunk_index: int
is_part_of: Document # edge to the parent Document
contains: List[Entity] = None # edges to the entities inside it
metadata: dict = {"index_fields": ["text"]} # which field gets embeddedis_part_of and contains look like ordinary type hints, but Cognee reads them at runtime and turns each typed field into a graph edge between DataPoint nodes. The index_fields entry inside metadata declares which field gets embedded, so a single class describes both the graph layer and the vector layer. In Cognee, memory is a modeling exercise.
The pipeline itself is composable. Each step in the default_tasks list above is a Task, and those tasks chain into a pipeline you can edit. The default cognify chain classifies, chunks, extracts a graph and summarizes, then adds data points and foreign-key edges. Storage spans three pluggable layers, graph DB (Kuzu-based “ladybug” by default, or Neo4j, Neptune, Postgres), vector DB (LanceDB default, pgvector, Chroma), and relational DB (SQLite or Postgres). Search is a large enum (SearchType), with GRAPH_COMPLETION (vector-seeded triplet search plus an LLM) as the flagship alongside RAG_COMPLETION, CHUNKS, SUMMARIES, CYPHER, NATURAL_LANGUAGE, TEMPORAL, and more.
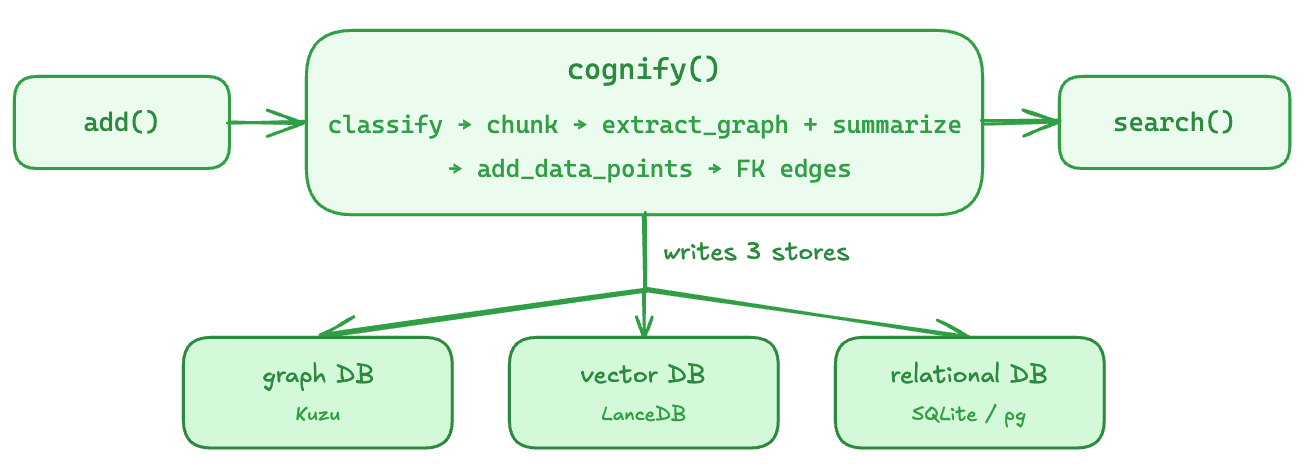
Cognee handles the same fact in three explicit stages. You add both statements as raw text, still unstructured. You call cognify, which chunks the text, extracts entities and typed edges, and writes them into the graph, vector, and relational stores together. A GRAPH_COMPLETION search seeds the lookup with vectors, walks the matching triples, and hands them to an LLM that composes the answer. Unlike the others, Cognee makes the build step explicit. You decide when the graph rebuilds rather than rebuilding on every write, and with temporal mode on, old and new locations coexist as dated events.
Cognee adds two more features. First, ontology grounding. An OWL/RDF resolver validates LLM-extracted entities against a supplied ontology and stamps each node with an ontology_valid flag, so you can tell grounded entities from hallucinated ones. Second, structured-data ingestion built on dlt (data load tool) pulls relational sources in and derives foreign-key edges automatically, so a database becomes part of the graph.
Comparison
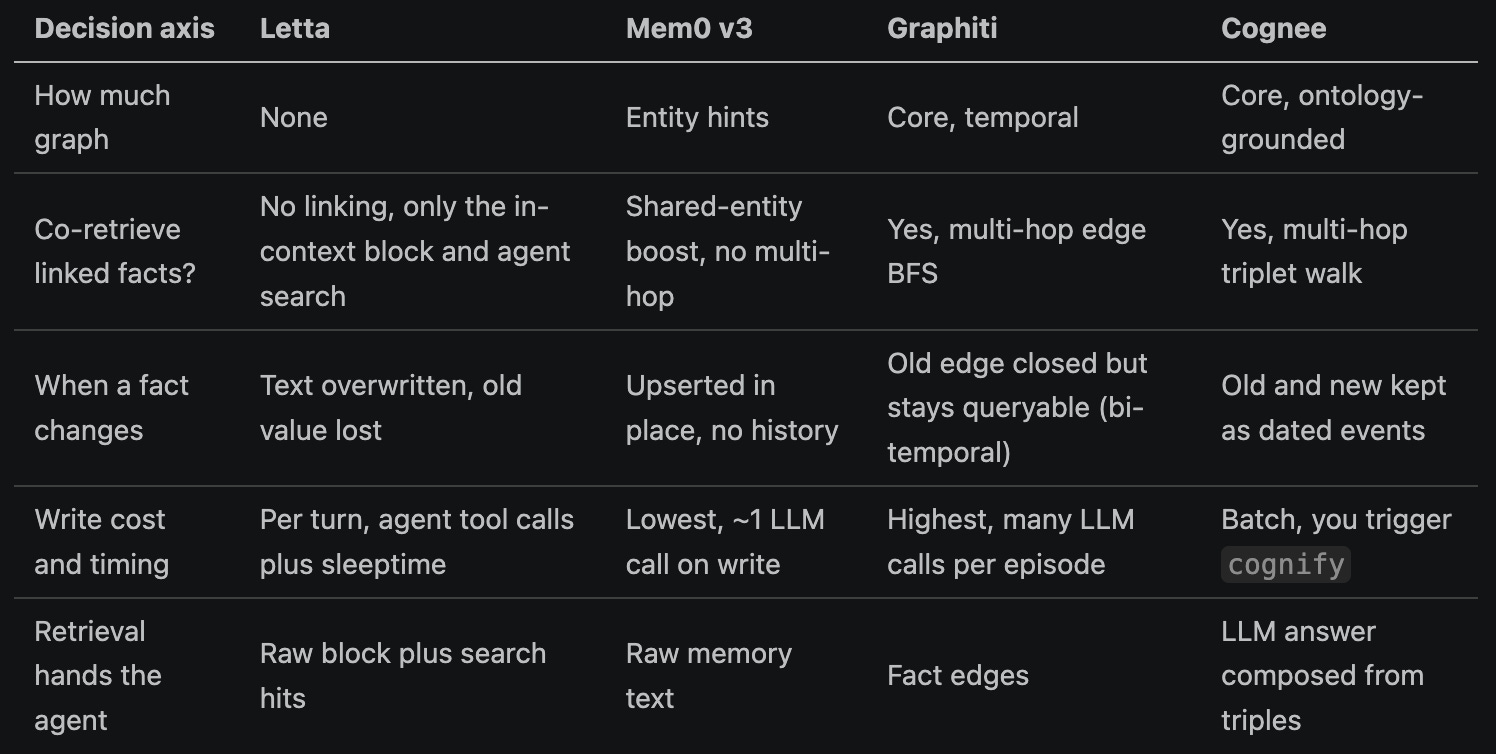
The table answers the post’s two questions side by side, co-retrieval and fact changes, plus what each costs and hands back.
The benchmark landscape
These systems are evaluated on a handful of benchmarks that test recall and reasoning over long conversation histories. Here is what each one measures.
LOCOMO (arXiv 2402.17753 / snap-research.github.io/locomo) tests recall and reasoning over very long multi-session dialogues, split into single-hop, multi-hop (combining facts stated in different sessions), temporal, open-domain, and adversarial categories. Reported by Mem0, Graphiti (Zep), and Letta.
LongMemEval (arXiv 2410.10813 / xiaowu0162.github.io/long-mem-eval) runs 500 questions over long chat histories testing five abilities, info extraction, multi-session reasoning, temporal reasoning, knowledge updates, and abstention. Reported by Mem0 and Graphiti (Zep).
HotPotQA (arXiv 1809.09600 / hotpotqa.github.io) is multi-hop QA over Wikipedia, every answer needs reasoning across two or more paragraphs, scored by Exact Match and F1. Reported by Cognee.
BEAM (arXiv 2510.27246, ICLR 2026) probes fact tracking, information updates, contradiction resolution, and temporal order over conversations up to 10M tokens, ten memory abilities in one suite. Reported by Mem0.
Unsurprisingly, each vendor’s own benchmark shows it winning.
But the numbers are not directly comparable. Mem0’s 92.5 and Letta’s 74.0 are both LLM-as-judge scores, yet each vendor runs its own answer model, judge model, and judge prompt, on different question subsets (Letta drops the adversarial category and runs gpt-4o-mini), so the gap reflects the eval harness as much as the memory system. Continua AI’s “The LoCoMo Fair Fight“ showed a model swap alone (gpt-4o-mini to gpt-4.1-mini) moved scores about 10 points. LOCOMO’s conversations run only about 16k to 26k tokens, inside modern context windows, so scores do not transfer to long agentic tasks. Zep’s “Lies, Damn Lies & Statistics: Is Mem0 Really SOTA?” disputed Mem0’s SOTA claim, arguing that the benchmark was flawed and that Mem0’s comparison ran a misconfigured Zep implementation. Newer benchmarks built to replace it, LongMemEval, MemoryArena (arXiv 2602.16313), Locomo-Plus (arXiv 2602.10715), and Hindsight from Vectorize, signal the field has moved on, though none has consolidated into a standard yet.
What it comes down to
The benchmarks blur the comparison, but the design behind these four does not. Step back from the numbers and the “how much graph” spectrum resolves into two separate questions it had been running together. Whether reads need to traverse, hopping fact to fact for “who owns the dog that had the checkup,” and whether writes need to keep history when a value changes.
The graph also charges up front. Ingestion burns LLM calls to extract and resolve nodes and edges, so the cost lands on write and pays back only on reads that traverse or look back. That asymmetry is what the four are really arguing about. Letta never built a graph, and Mem0 removed its own after its paper showed the variant lost on single- and multi-hop recall, ran 3x slower, and cost 2x the tokens. Graphiti and Cognee built around the workloads where traversal and history matter most.
One adjacent space is easy to confuse with these. Document-RAG systems like Microsoft GraphRAG and LightRAG also build knowledge graphs, but from static corpora in a single batch pass rather than from incremental agent interactions. GraphRAG is the batch-recompute foil to Graphiti’s live ingestion, and Cognee benchmarks against LightRAG on HotPotQA. They build the same data structure for a different problem.