
[AgentFS] A Copy-on-Write Filesystem Agents Can Write Without Consequences
Design · SQLite-backed isolation for AI agents that need filesystem read/write access

AI agents become more useful as their permission boundaries expand. To do real work, they need to read and write files, install packages, and edit configurations. But giving an agent direct access to your host filesystem is risky. A single hallucinated rm -rf can be irrecoverable.
Overview
Agents need isolation so changes don’t leak to the host, auditability so every file operation is queryable after the fact, and reproducibility to restore state at any point. Docker and chroot solve isolation, but they don’t give you a queryable audit trail, and they don’t run in environments without a Linux kernel.
AgentFS provides a copy-on-write overlay filesystem backed by SQLite. An entire agent session lives in a single .db file. You can checkpoint state with a file copy, query every operation with SQL, and throw the whole thing away when you’re done.
The Two-Layer Architecture
AgentFS implements a two-layer overlay. The base layer is a read-only view of the host filesystem (or any remote filesystem implementing the FileSystem trait). The delta layer is a writable AgentFS instance backed by SQLite. All agent modifications go to the delta layer. The base layer stays read-only.
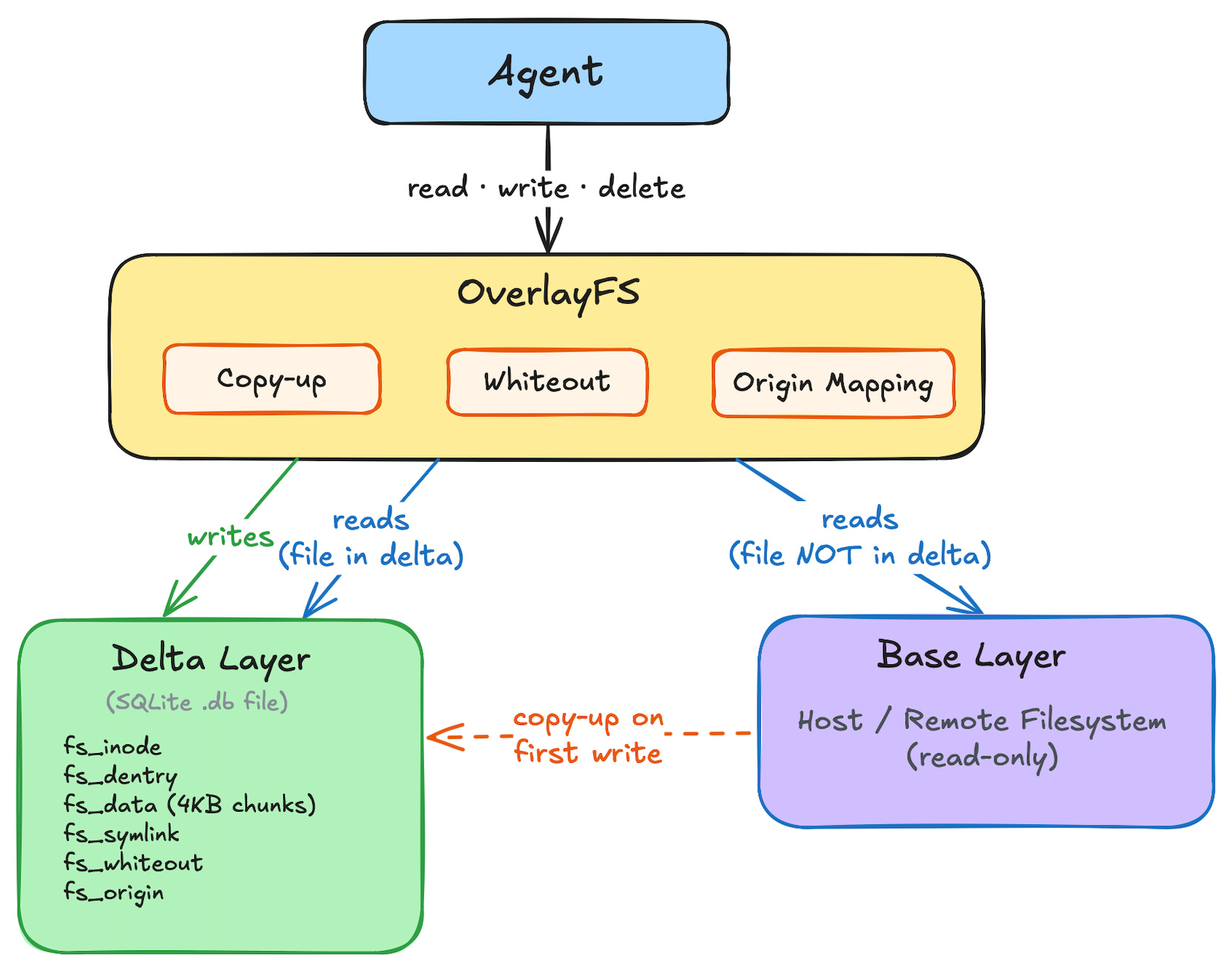
Copy-up handles lazy duplication when an agent opens a base-layer file. Whiteout records track deletions without touching the base. Origin mapping keeps inode numbers stable after copy-up so the kernel’s dentry cache stays consistent. The next section shows how these fit together, then we dig into each one.
Reads and Writes
When an agent reads or writes a file, which layer handles it? There is no content-level merging between layers. One layer always wins. Delta if the file exists there, base otherwise. Once a file is opened for any reason, it gets copied up, and from that point on all I/O goes to delta.
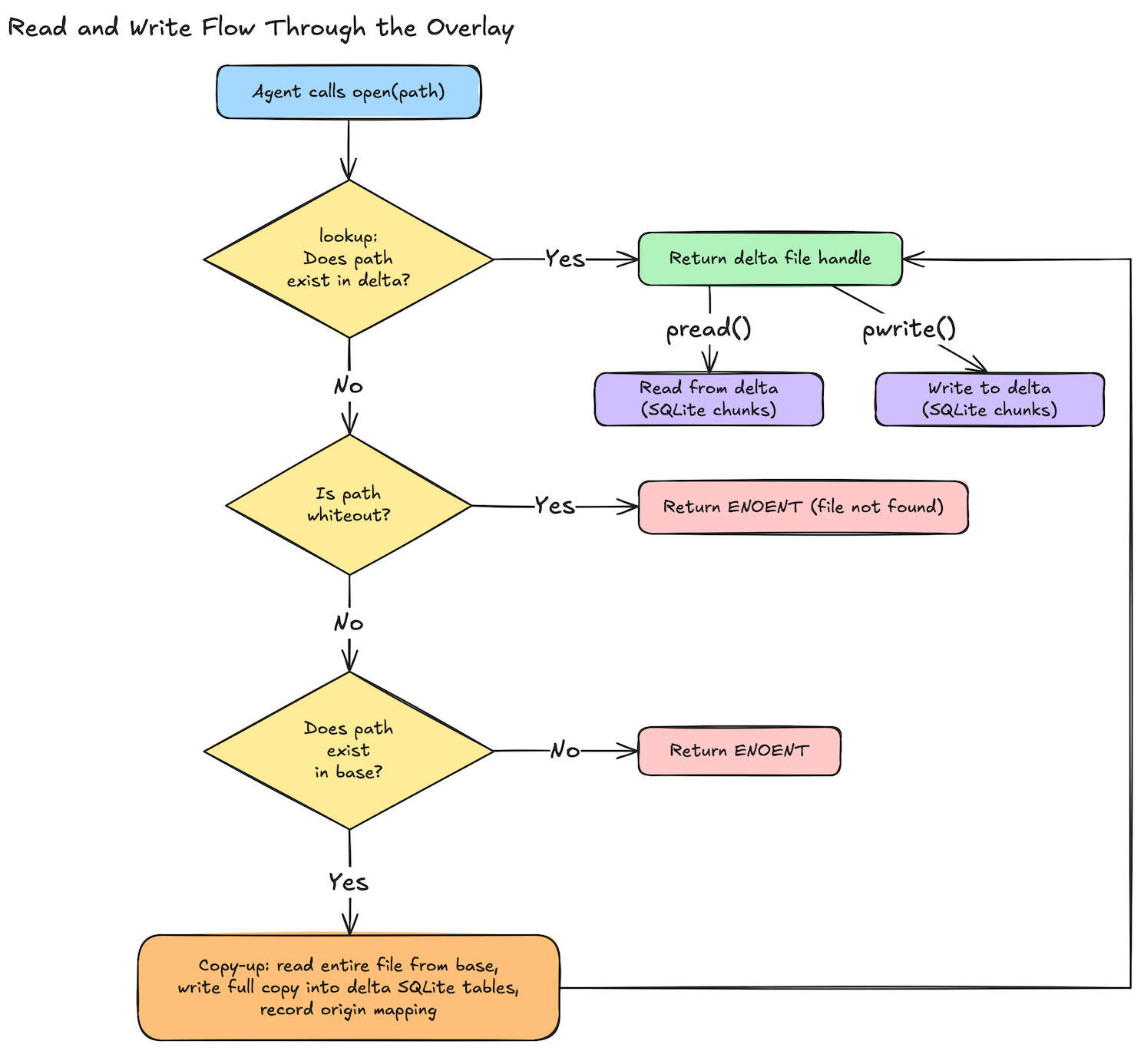
Path resolution: delta-first lookup
Every file operation starts with a path lookup. The overlay checks the delta layer first. If the file exists in delta (created fresh by the agent or copied up by a previous operation), the delta version wins. The base layer is never consulted.
If the file isn’t in delta, the overlay checks the whiteout set. If the path or any ancestor has a whiteout entry, the file is treated as deleted and the base layer is skipped entirely.
Only when the file is absent from delta and has no whiteout does the overlay fall through to the base layer.
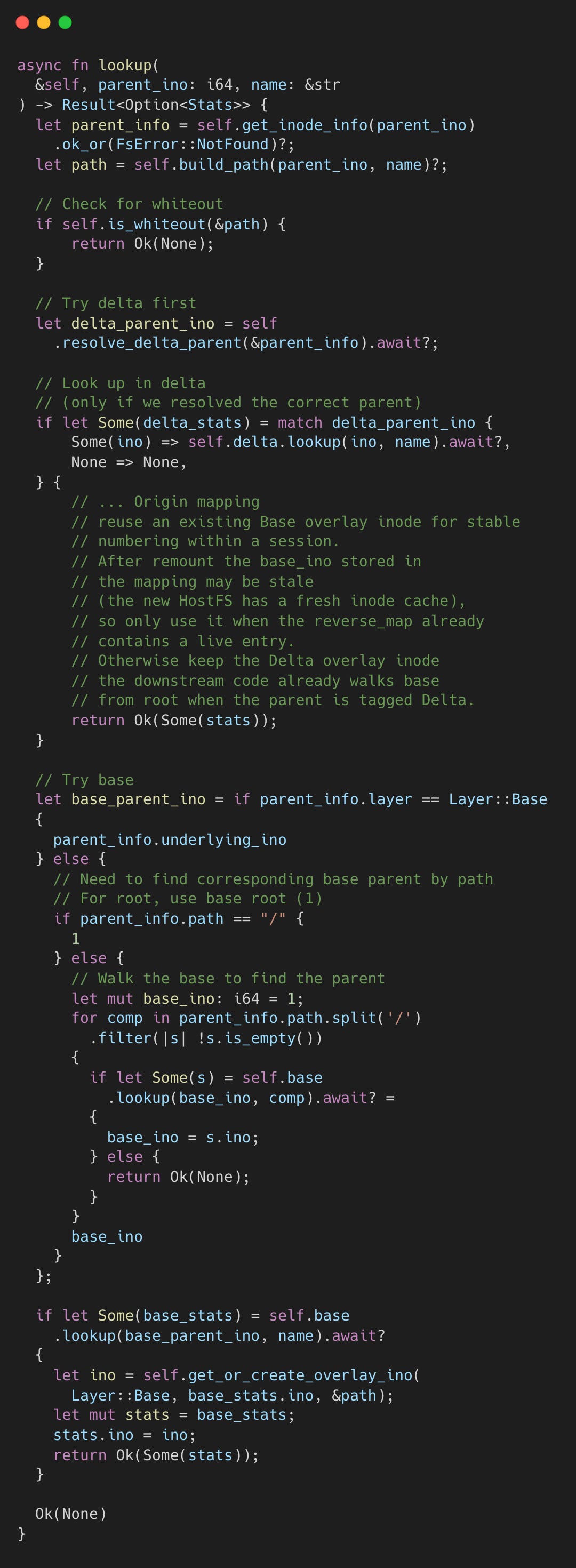
The read path: eager copy-up on open
open() always triggers copy-up for base-layer files, even for read-only opens. Once open() returns, the file handle points to the delta layer regardless of where the file originally lived.
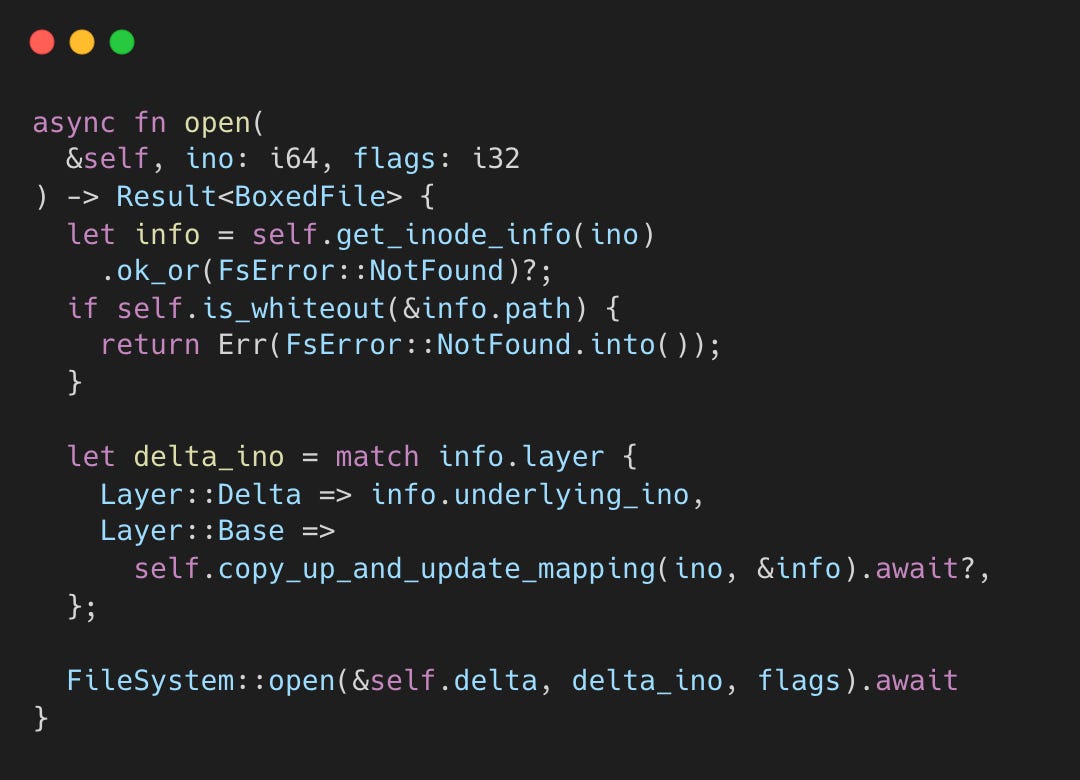
This means subsequent pread() calls on the returned handle go directly to the delta layer’s SQLite chunk storage. There’s no read-time merging, no “check delta then fall through to base for missing chunks.” The entire file was copied during open(), and from that point forward delta is the single source of truth.
The write path: delta-only, always
Writes are straightforward because open() already ensured the file lives in delta. A pwrite() call on the file handle writes directly to the delta layer’s fs_data chunks. No base layer involvement, no merging.
Files the agent creates from scratch skip copy-up entirely. They’re born in the delta layer and stay there.
Directory reads: merging both layers
Directory reads are the exception to the “one layer wins” rule. A readdir() call must merge entries from both layers and filter out whiteouts. The implementation collects delta entries into a HashSet, then adds base entries (skipping duplicates and whiteouts), and returns a sorted result:
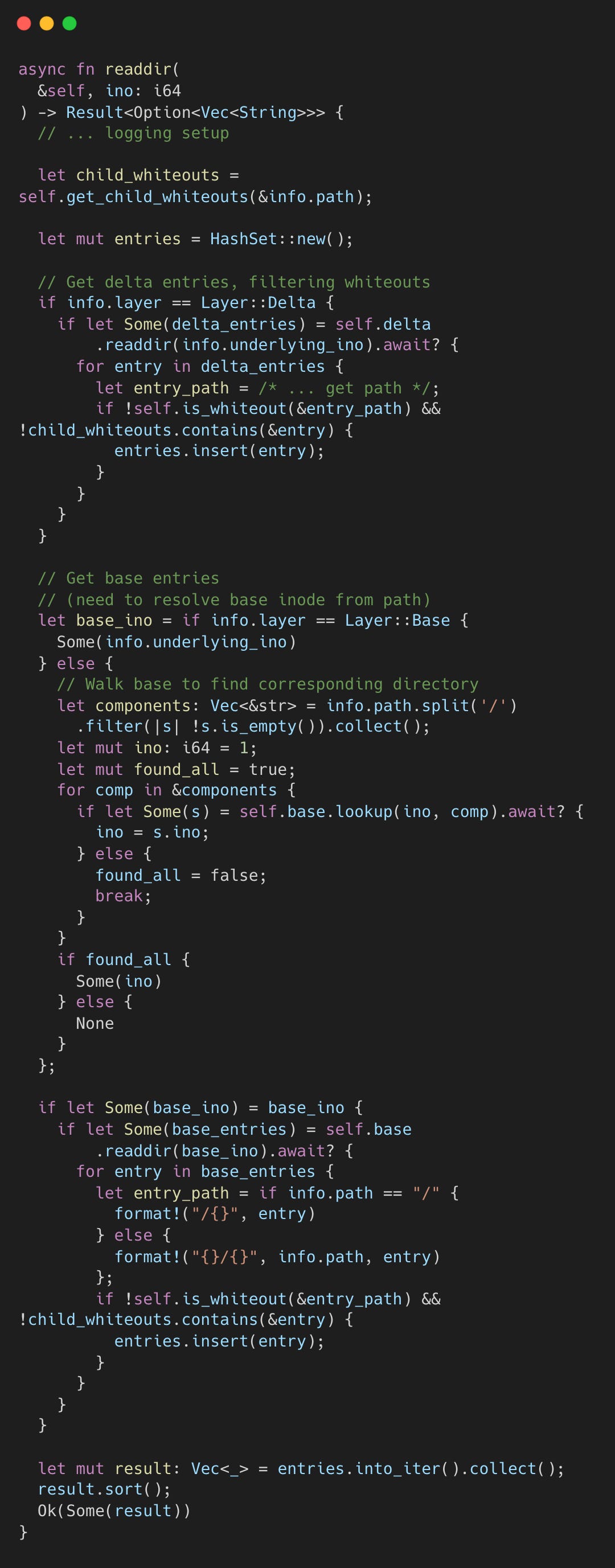
The readdir_plus variant takes this further. Instead of listing names and then issuing a separate getattr call per entry to fetch metadata (size, permissions, timestamps), it fetches names and full stats in a single pass. It loads all base-layer entries into a HashMap, then applies delta-layer entries on top. Any delta entry with the same key overwrites the base entry. A single directory listing grabs all metadata in bulk instead of making a separate call per file.
Why not store modified chunks and merge with base layer?
Storing only modified chunks in delta and reading unmodified chunks from base would save space on copy-up. But it would complicate every read with a “check delta, fall back to base” branch and make the .db file non-self-contained. The eager copy-up trades some disk space for simpler reads and a fully portable delta file.
What about base layer changes?
AgentFS assumes the base layer is static for the duration of a session. Files already copied up to delta are permanently decoupled from their base originals. Files not yet copied up will reflect whatever the host has at the time of access, but this is incidental, not a consistency guarantee.
The only way to pick up base layer changes is to remount: create a new OverlayFS with a fresh HostFS while reusing the existing .db file. On init, the overlay reloads whiteouts and origin mappings from SQLite, then populates its in-memory caches on demand from the now-current base. Files already in delta remain untouched.
Inside the Overlay
Here’s what happens under the hood.
Copy-up
When an agent modifies a base-layer file, AgentFS reads it in full, writes it into the delta’s SQLite tables, then applies the modification. Subsequent operations hit the delta copy. This is the architecture’s most visible cost: modifying a large base file triggers a full copy before the write proceeds. For agent workloads that read far more than they write, it’s the right tradeoff.
The implementation checks whether the file has already been copied, creates any missing parent directories in the delta layer, then copies content based on file type.
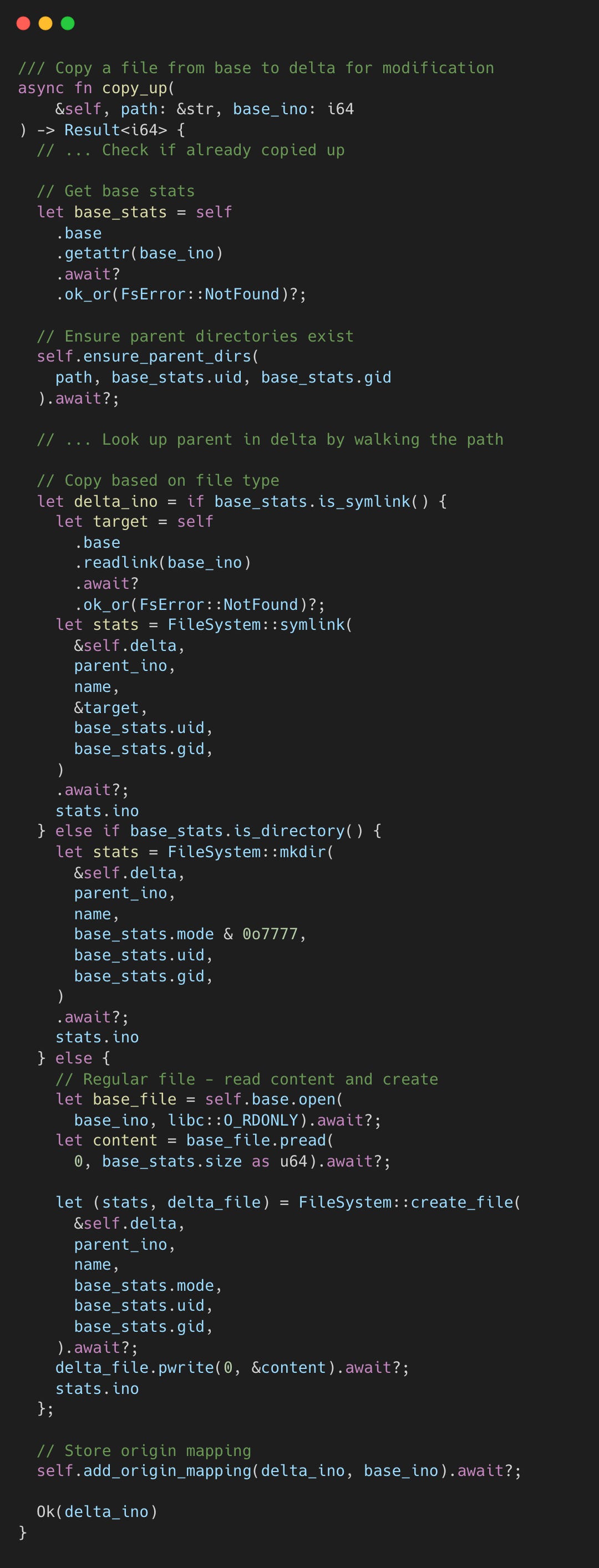
Copy-up changes a file’s inode number because the delta layer assigns its own auto-incrementing IDs. To keep the kernel’s dentry cache consistent, AgentFS stores a mapping from the new delta inode back to the original base inode in fs_origin. This is analogous to Linux overlayfs’s trusted.overlay.origin extended attribute. On every subsequent lookup, the overlay checks this mapping and returns the original inode number. The file silently moved from base to delta, but the kernel never sees the difference.
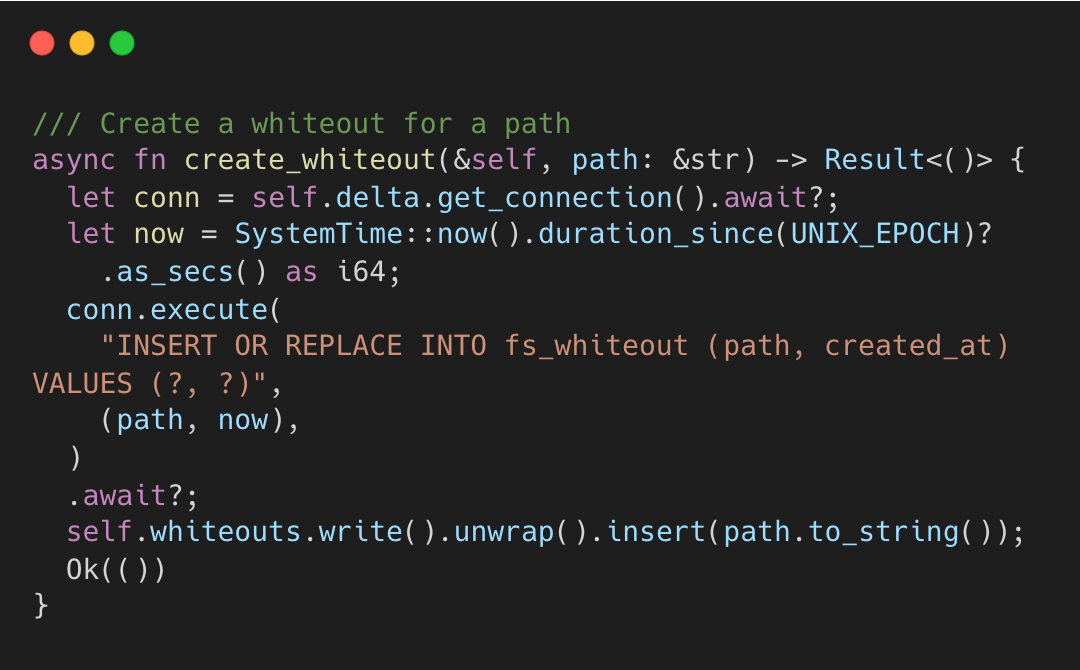
Whiteout Records
When an agent deletes a file from the base layer, AgentFS inserts a row into fs_whiteout rather than modifying the base. A small SQL row replaces a destructive operation.
Before any base layer lookup, the overlay checks the whiteout set. If the path or any ancestor has a whiteout entry, the file is treated as non-existent. The whiteout set loads into an in-memory HashSet<String> at mount time for O(1) checks and persists to SQLite so it survives remounts.
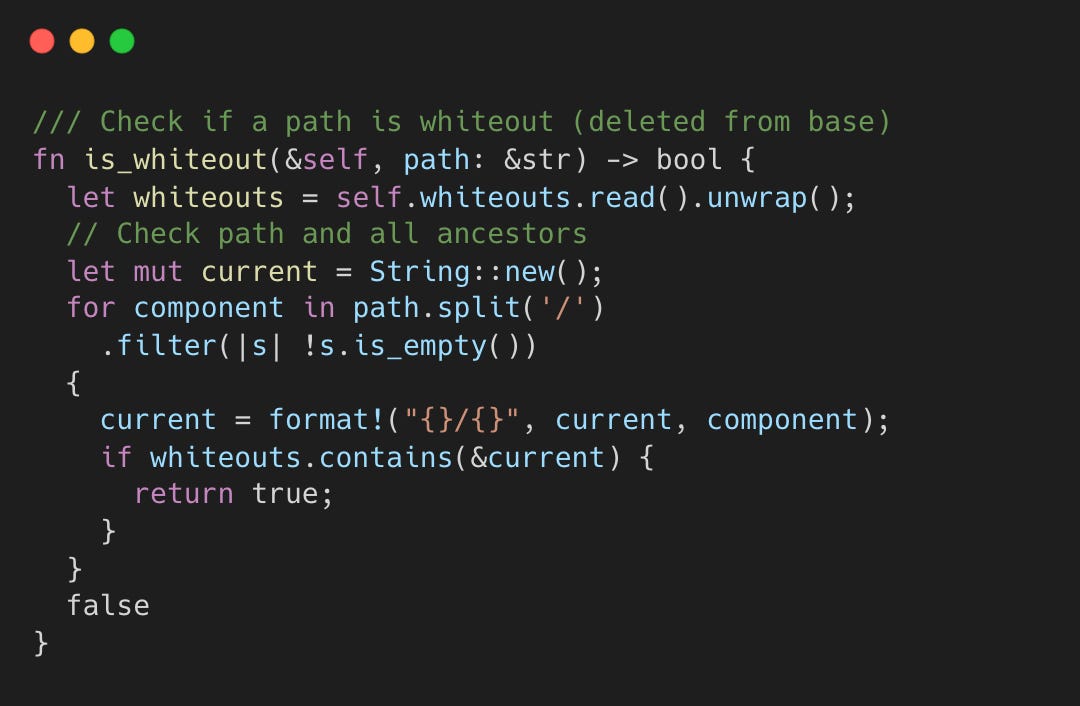
If /foo has a whiteout, /foo/bar/baz is also invisible.
The SQLite Delta Layer
All delta state lives in SQLite tables defined by the AgentFS specification. The schema is a Unix-like inode filesystem, created during initialization.
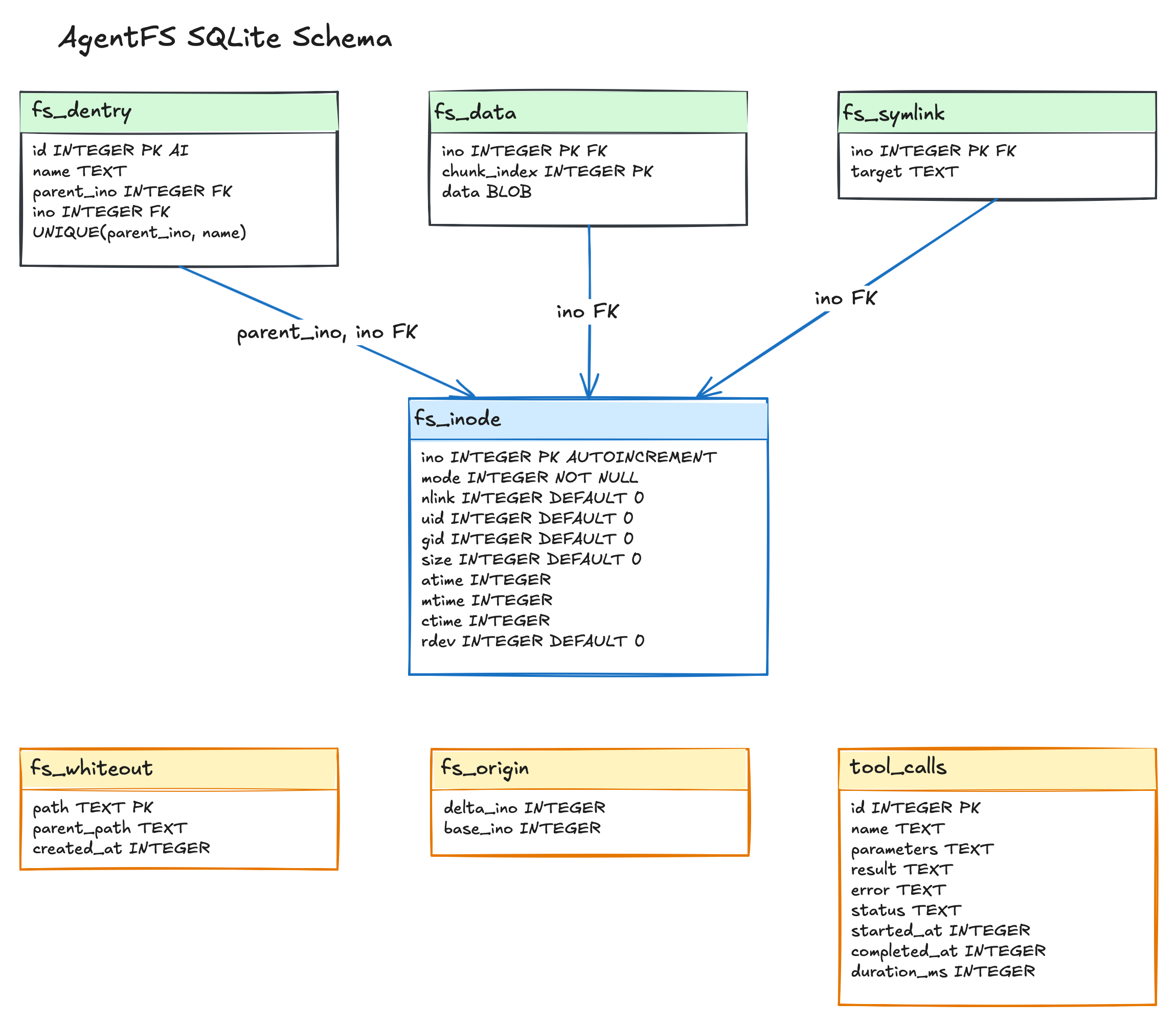
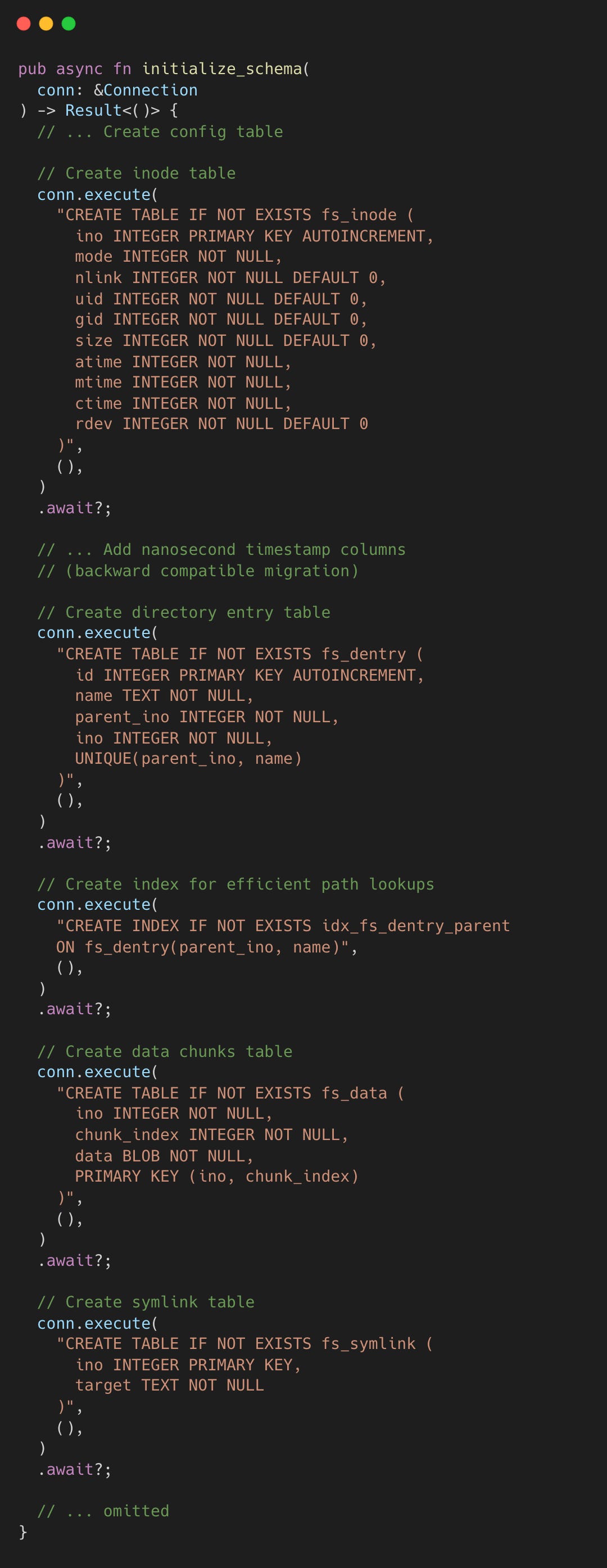
fs_inode stores metadata (mode, uid, gid, size, timestamps with nanosecond precision). fs_dentry maps (parent_ino, name) pairs to inode numbers with a unique constraint and an index for O(1) lookups. fs_data stores file content in fixed 4096-byte chunks, enabling efficient random-access reads without loading entire files. fs_symlink stores symlink targets. fs_whiteout tracks deleted paths. fs_origin tracks copy-up origin inodes.
The chunk-based storage in fs_data is worth calling out. Each chunk is keyed by (ino, chunk_index) with a fixed 4096-byte size (except the last chunk). To read bytes at offset N, you compute chunk_index = N / 4096 and offset_in_chunk = N % 4096. This avoids loading a 500MB file into memory just to read the last 4KB.
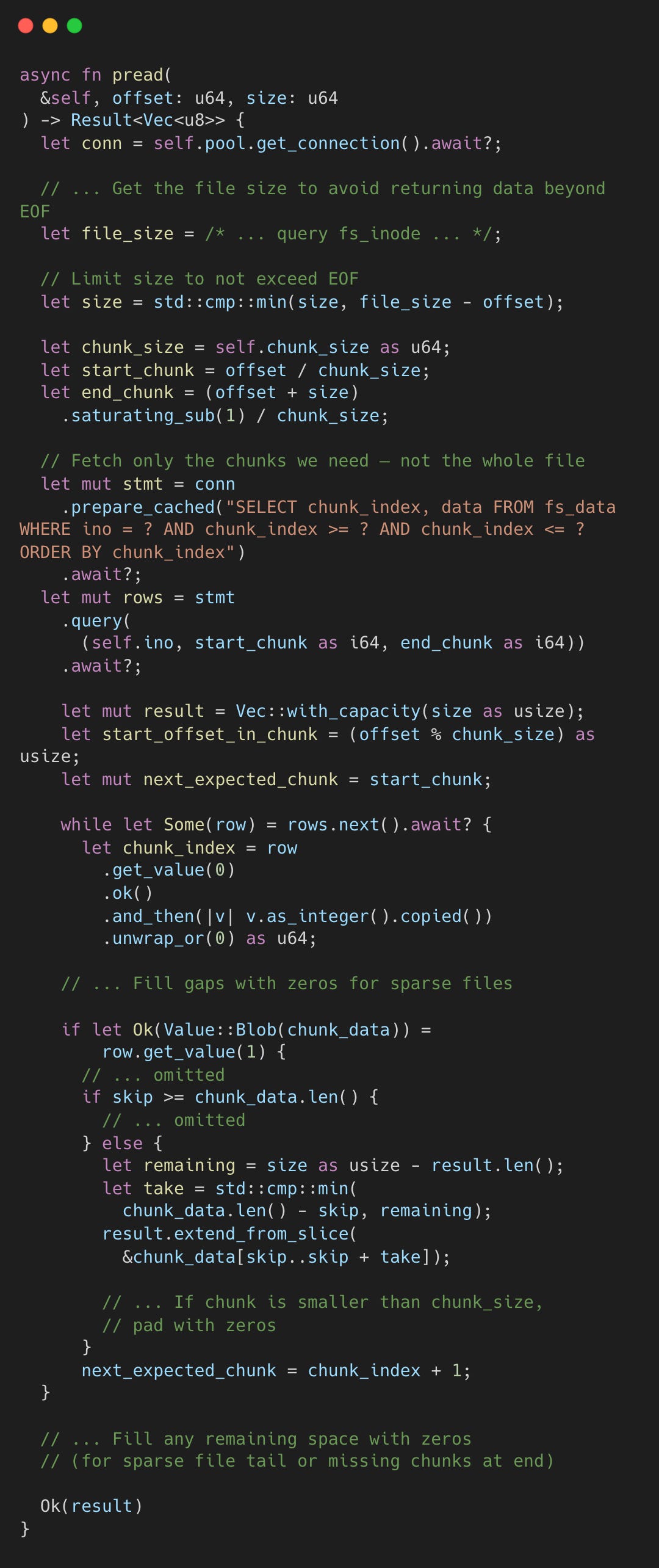
Writes mirror this logic. A partial-chunk write uses read-modify-write: fetch the existing chunk, splice in the new bytes, then INSERT OR REPLACE the whole chunk back. A full-chunk write skips the read entirely.
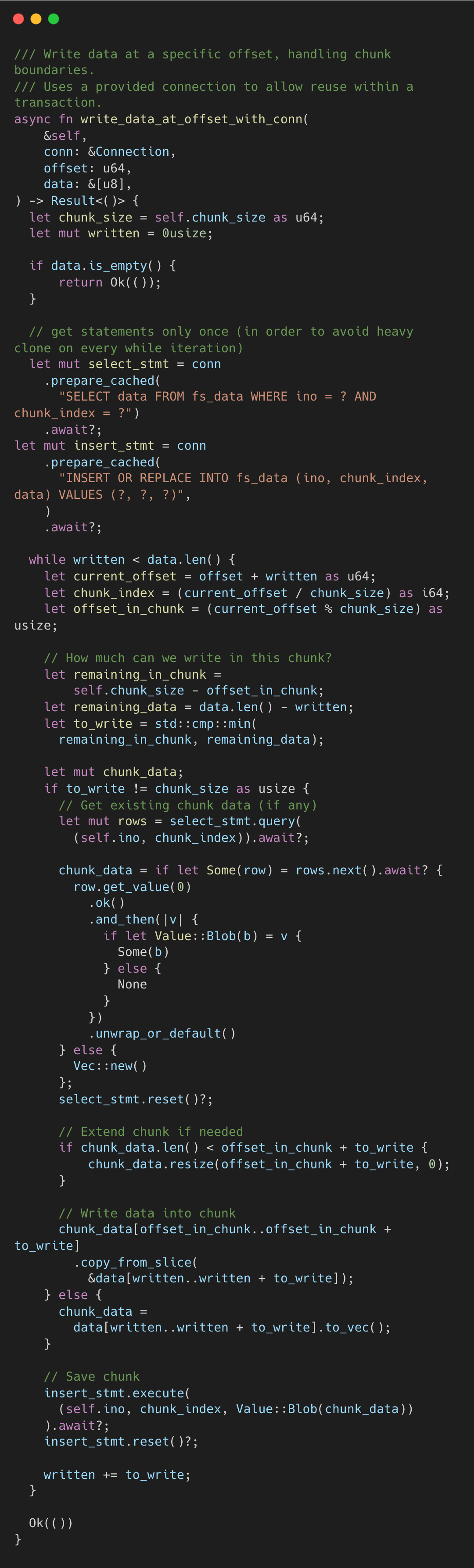
Beyond the filesystem itself, the SQLite file also contains tool_calls. The tool_calls table is an insert-only audit log of every tool invocation with parameters, results, and timing.
The entire agent session, filesystem state and tool history alike, is one portable, queryable file.
Performance Enhancements
Several caching layers keep the overlay performant despite the extra indirection.
The overlay inode maps live in the OverlayFS struct behind RwLocks: inode_map translates overlay inodes to their underlying layer info, reverse_map provides the inverse lookup from (layer, underlying_ino) to overlay inode, and path_map maps virtual paths to overlay inodes. These are unbounded HashMaps that grow on demand, avoiding repeated base-layer traversals during path resolution.
The in-memory whiteout set is a HashSet<String> loaded from fs_whiteout at mount time. Every lookup checks this set before touching the base layer. Without it, every base lookup would require a database query.
The dentry cache in the delta layer is an LRU cache of 10,000 entries mapping (parent_ino, name) to child_ino. For a path like /a/b/c/d, this reduces four database queries to zero on cache hits. It is implemented with a Mutex<LruCache> from the lru crate and invalidated on unlink and rmdir operations.
Major Contributions
The project is driven by Turso.
This post was written with galleylabs.ai.