
[AI-Scientist-v2] Inside the Autonomous AI Scientist Featured in Nature
Design · Four design decisions in AI Scientist v2 that keep the LLM from fabricating its own citations, numbers, and figures

In March 2026, Nature published a paper about an autonomous AI pipeline that had written a manuscript that passed peer review at an ICLR 2025 workshop. The system is called AI Scientist v2. Given a topic in machine learning, it runs ideation, experimentation, plotting, citation gathering, write-up, and review without a human in the loop. The experiments themselves are PyTorch scripts that the agent writes, runs on an NVIDIA GPU, and logs to .npy files.
LLMs can hallucinate citations, numbers, figure captions, and novelty claims. v2 prevents this through four structural choices about what the LLM is allowed to see, when, and what gets verified at which layer.
The Pipeline in One Glance
Here is what actually runs when you launch.
SakanaAI/AI-Scientist-v2:launch_scientist_bfts.py#L217-L319
idea_to_markdown(ideas[args.idea_idx], idea_path_md, code_path)
# ... idea / config setup omitted ...
perform_experiments_bfts(idea_config_path) # 4-stage tree search
aggregate_plots(base_folder=idea_dir, model=args.model_agg_plots)
save_token_tracker(idea_dir)
citations_text = gather_citations(idea_dir, ...) # 20-round Semantic Scholar loop
for attempt in range(args.writeup_retries):
writeup_success = perform_writeup(...) if args.writeup_type == "normal" \
else perform_icbinb_writeup(...)
if writeup_success: break
pdf_path = find_pdf_path_for_review(idea_dir)
review_text = perform_review(paper_content, client_model, client)
review_img_cap_ref = perform_imgs_cap_ref_review(client, client_model, pdf_path)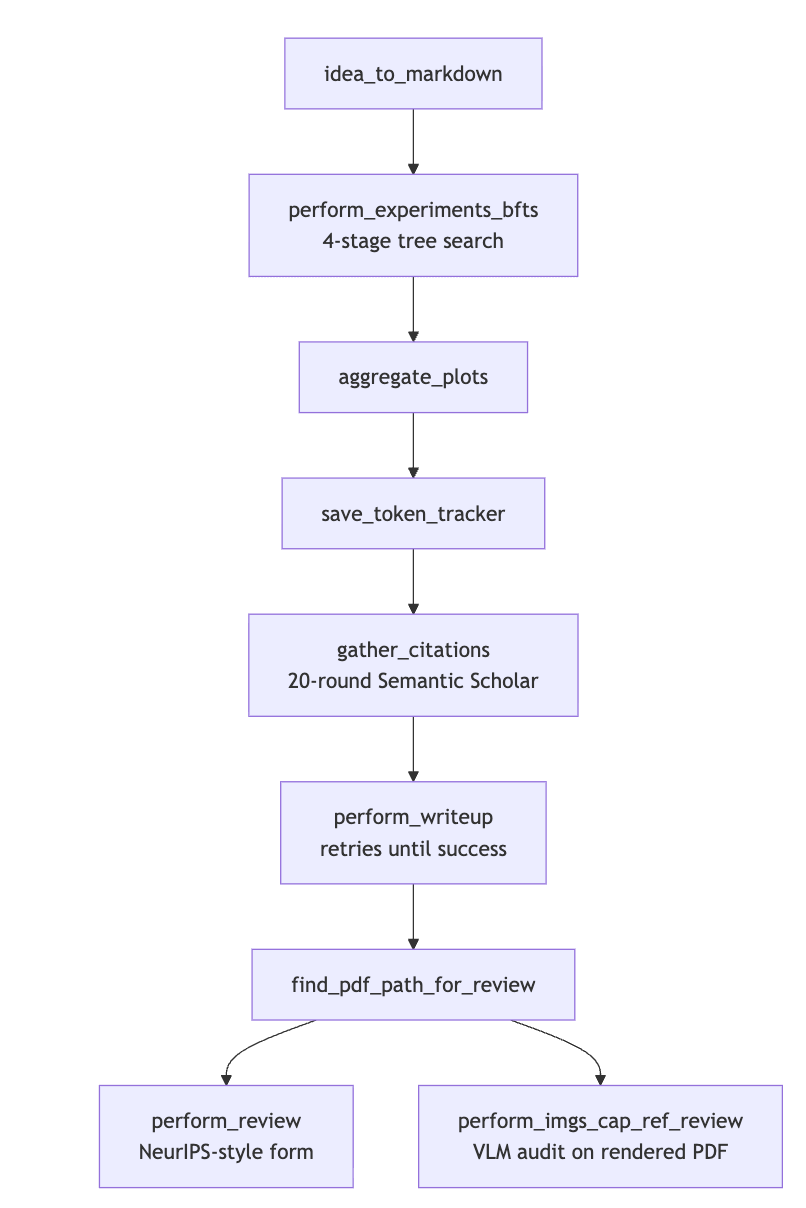
That is the whole orchestrator. About a dozen sequential function calls and no central agent class. Four unique models cover five jobs. Claude 3.5 Sonnet runs the tree search. o3-mini writes the plotting code. o1-preview writes the LaTeX. gpt-4o does triple duty as the citation gatherer, the review model, and the VLM that audits the figures. All four are default values in bfts_config.yaml and the launcher’s argparse, so a user can swap any of them at the command line.
The perform_experiments_bfts call is itself a four-stage progression. The stages are initial_implementation, baseline_tuning, creative_research, and ablation_studies, and the best node from one stage seeds the next.
What Makes This Autonomous, Not Just Automated
“Automated” would be a fixed script that runs a prewritten experiment and fills in a report. AI Scientist is doing something more specific and more interesting. It is autonomous inside a scaffold. A human gives it a workshop brief or starting idea, but after launch the system moves through the research loop itself: turn an idea into an experiment spec, write code, execute it, inspect plots, choose what to try next, gather citations, write LaTeX, compile the PDF, and review the paper.
The scaffold is the important part. The agent is not wandering an open-ended internet. AgentManager hardcodes a research campaign with four roles: first get any implementation working, then tune the baseline, then explore novel improvements, then run ablations.
SakanaAI/AI-Scientist-v2:agent_manager.py#L143-L167
self.main_stage_dict = {
1: "initial_implementation",
2: "baseline_tuning",
3: "creative_research",
4: "ablation_studies",
}
A normal benchmark agent tries to maximize one score. AI Scientist has to make a result publishable: establish feasibility, improve the baseline, test across more datasets, produce a research contribution, and then isolate which components mattered. The scientific judgment is not one magical model call. It is a stage machine that keeps asking a different research question at each phase.
Inside each phase, the search loop has its own autonomy. ParallelAgent runs up to four workers by default, and _select_parallel_nodes decides whether each worker drafts a new root, debugs a failed leaf, or improves the best unprocessed good node. Stage 2 reuses the best Stage 1 node for hyperparameter tuning, and Stage 4 reuses the best Stage 3 node for ablation. That is a bounded exploration/exploitation loop, not a single prompt.
The system also makes judgment calls where a human researcher would normally pause. Journal.get_best_node picks among candidate implementations and warns the model not to over-trust validation loss, since nodes may have different objectives or training details. AgentManager checks stage completion with a {is_complete, reasoning, missing_criteria} schema. The VLM plot check writes is_buggy_plots, gating whether a node advances.
Finally, it does not stop at “the code ran.” The write-up side behaves like the back half of a research workflow. gather_citations runs up to 20 Semantic Scholar rounds, caches progress, and dedupes by title. The write-up loop compiles LaTeX, checks page limits, flags unused or invalid figures, runs chktex, has a VLM review image-caption-reference alignment, and reflects on the PDF. Then perform_review applies a NeurIPS-style review form.
The right mental model is not “one autonomous scientist brain.” It is a closed research workflow made of specialized loops, chained so each loop’s output becomes the next loop’s evidence. Plot review feeds node selection. Node selection feeds stage transition. Stage transition feeds the next experiment. Experiment summaries feed plotting and citations. The compiled PDF feeds review. That is also why hallucination is the central risk. Once the system can write code, pick winners, cite papers, and describe its own figures, every place where a claim becomes an artifact needs a structural guardrail.
Now let’s look at the four guards against hallucination.
Defense 1. Force a Literature Search Before Ideation Can Finish
The ideation loop runs in perform_ideation_temp_free.py. The agent has exactly two actions it can emit, SearchSemanticScholar and FinalizeIdea. Look at the closing line of the system prompt.
SakanaAI/AI-Scientist-v2:perform_ideation_temp_free.py#L61-L96
system_prompt = f"""You are an experienced AI researcher who aims to propose
high-impact research ideas...
# ... omitted ...
Note: You should perform at least one literature search before finalizing
your idea to ensure it is well-informed by existing research."""Combined with the two-action ReAct setup, an idea cannot reach FinalizeIdea without at least one Semantic Scholar tool call landing first.
This matters because the arXiv 2502.14297 evaluation found that AI Scientist sometimes “rediscovered” things like micro-batching as if they were novel. Without the forced lookup, every claim of novelty could be unverified.
Defense 2. Hide the Numbers From the Plotting Model
The plotting model is asked to write a Python script that loads experiment results and produces final figures. The natural failure mode is obvious. If you paste the raw arrays into the prompt, the LLM can rewrite them when it generates plots.
SakanaAI/AI-Scientist-v2:perform_plotting.py#L52-L86
def build_aggregator_prompt(combined_summaries_str, idea_text):
return f"""
We have three JSON summaries of scientific experiments: baseline, research, ablation.
They may contain lists of figure descriptions, code to generate the figures,
and paths to the .npy files containing the numerical results.
# ... omitted ...
IMPORTANT:
- The aggregator script must load existing .npy experiment data from the
"exp_results_npy_files" fields (ONLY using full and exact file paths in
the summary JSONs) for thorough plotting.
# ... omitted ...
4) Do not hallucinate data. Data must either be loaded from .npy files
or copied from the JSON summaries.
"""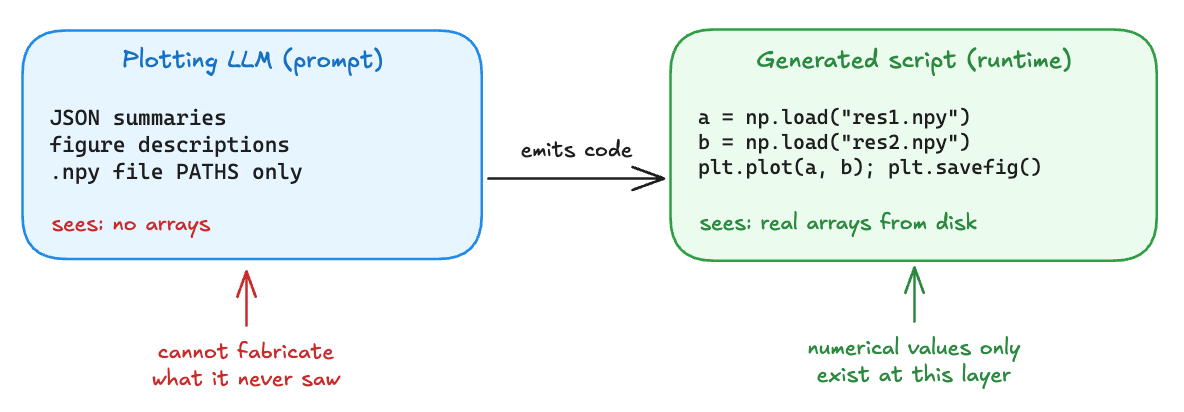
The aggregator prompt only contains .npy paths. To plot anything, the generated Python has to call np.load(path) at runtime. filter_experiment_summaries also strips the metric field out of the plot-aggregation summary, so the LLM never sees the raw arrays and never sees the headline numbers, and it cannot rewrite what it cannot read.
Defense 3. Re-Run the Winner With Different Seeds
After each main stage of the tree search, the best implementation goes through _run_multi_seed_evaluation.
SakanaAI/AI-Scientist-v2:parallel_agent.py#L1261-L1316
def _run_multi_seed_evaluation(self, node: Node) -> List[Node]:
# omitted: GPU bookkeeping
seed_nodes = []
futures = []
for seed in range(self.cfg.agent.multi_seed_eval.num_seeds):
# ... omitted ...
node_data["code"] = (
f"# Set random seed\nimport random\nimport numpy as np\nimport torch\n\n"
f"seed = {seed}\nrandom.seed(seed)\nnp.random.seed(seed)\n"
f"torch.manual_seed(seed)\n"
f"if torch.cuda.is_available():\n torch.cuda.manual_seed(seed)\n\n"
+ node_code
)
# ... submit to executor ...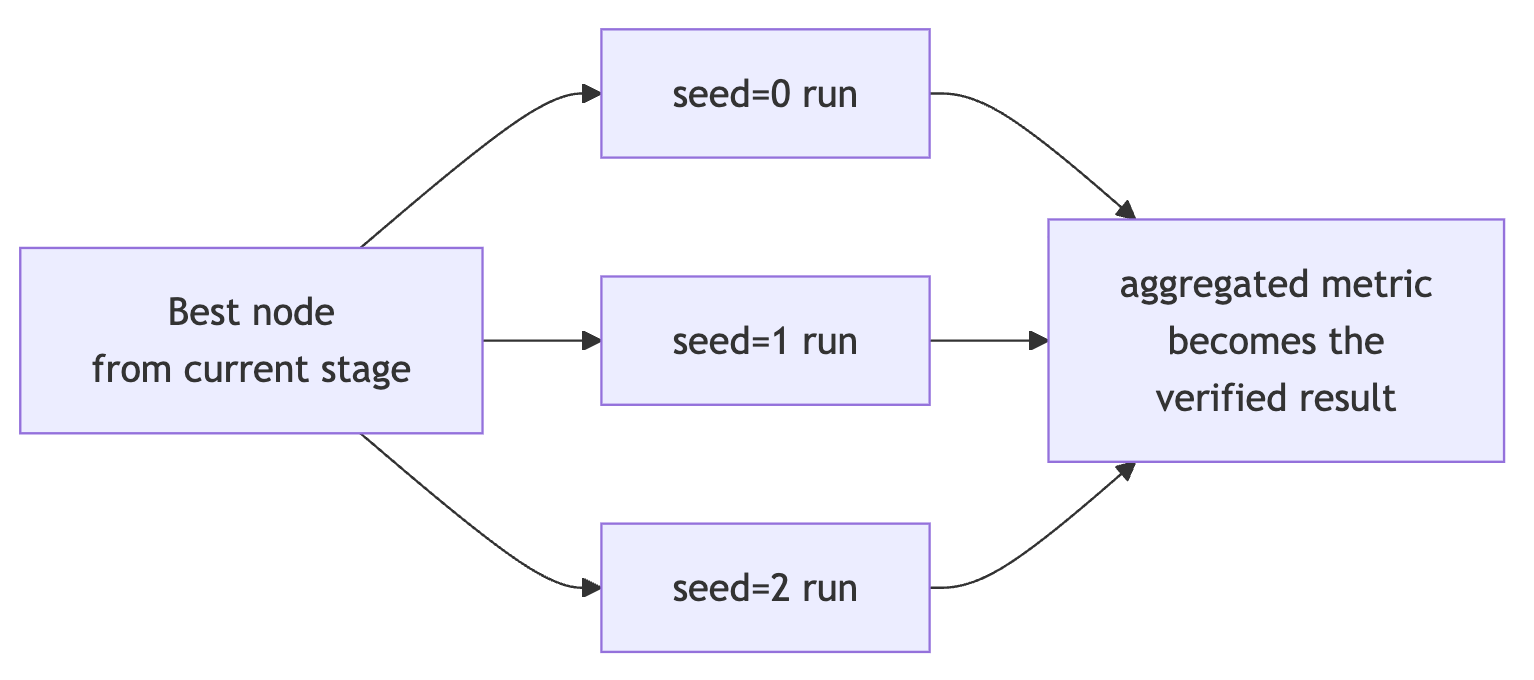
The default num_seeds is 3. The exact same code runs three times with different random seeds prepended. If the original “best” number came from a lucky initialization, the re-runs will out it before the result becomes a paper claim. It is a structural reflex baked into the search loop. The winner gets re-tested whether the LLM wants it to or not.
Defense 4. Audit the Rendered PDF, Not the LaTeX
The final write-up phase produces a LaTeX paper. A naive review would re-read the source LaTeX and check that the captions make sense, but AI Scientist does something different.
SakanaAI/AI-Scientist-v2:perform_vlm_review.py#L372-L386
def perform_imgs_cap_ref_review(client, client_model, pdf_path):
paper_txt = load_paper(pdf_path)
img_folder_path = os.path.join(
os.path.dirname(pdf_path),
f"{os.path.splitext(os.path.basename(pdf_path))[0]}_imgs",
)
if not os.path.exists(img_folder_path):
os.makedirs(img_folder_path)
img_pairs = extract_figure_screenshots(pdf_path, img_folder_path)
img_reviews = {}
abstract = extract_abstract(paper_txt)
for img in img_pairs:
review = generate_vlm_img_cap_ref_review(img, abstract, client_model, client)
img_reviews[img["img_name"]] = review
return img_reviewsAfter the LaTeX compiles, extract_figure_screenshots rasterizes every figure straight out of the rendered PDF. Each screenshot goes to a VLM with the figure’s caption and the surrounding main-text references. The VLM prompt asks whether the image, caption, and references actually agree.
This catches the failure mode the source-level reviewer cannot see. A LaTeX file can compile cleanly and still produce a figure that has nothing to do with its caption. By moving the audit after rendering, the gap between “the code compiles” and “the artifact makes sense” can be closed.
Design Choices and Impact
Each defense costs something. Mandatory tool calls slow ideation. Loading .npy files at runtime means the plotter has to run in a sandboxed Python process. Multi-seed evaluation triples the compute spent on the best node of each stage. PDF rasterization is more brittle than parsing LaTeX. The system pays these costs because the alternative is paying them later in retracted citations and faked figures.
The paper itself flags hallucination as a known limitation in the Limitations section of the Nature article. The authors note that generated manuscripts still cite non-existent papers and sometimes duplicate figures across sections.
If you are building an LLM pipeline that needs to produce checkable artifacts, the takeaway is short. Do not write “please do not hallucinate” into your system prompt. Audit your pipeline for places where the model is trusted, and rewrite those places into structural constraints.