
[Apache Hudi] ExternalSpillableMap: Handle Maps Too Big for Memory
Scalability · Scale record merges beyond memory limits with hybrid storage

Merging millions of existing records with updates requires matching keys. If the map exceeds available memory, the process fails. Apache Hudi solves this problem with a hybrid data structure that automatically spills to disk when memory is low.
Problem: Tracking Records During Updates
Data lake files are immutable; records cannot be edited in place. Updates go to separate log files. Merging logs with base files produces the final state.
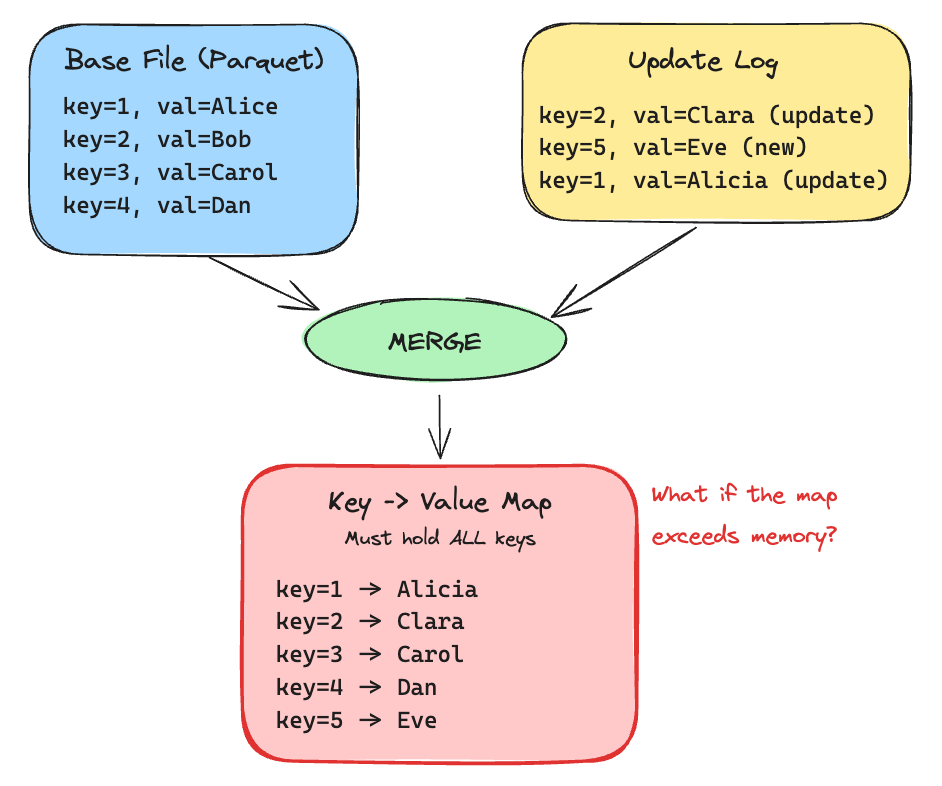
Merging requires a lookup map of all keys from log files to efficiently match updates against base file records.
For large datasets, this map can exceed executor memory. Hudi faces this during compaction and read operations.
Naive solutions fail:
Pure in-memory: OOM on large datasets.
Pure disk-based: Slow random access.
Fixed-size cache: Data loss or corruption.
Hudi’s ExternalSpillableMap stays in memory until a threshold, then spills to disk.
How It Works
ExternalSpillableMap maintains two maps: a fast in-memory HashMap and a lazily-initialized DiskMap.
ExternalSpillableMap.java#L59-L90
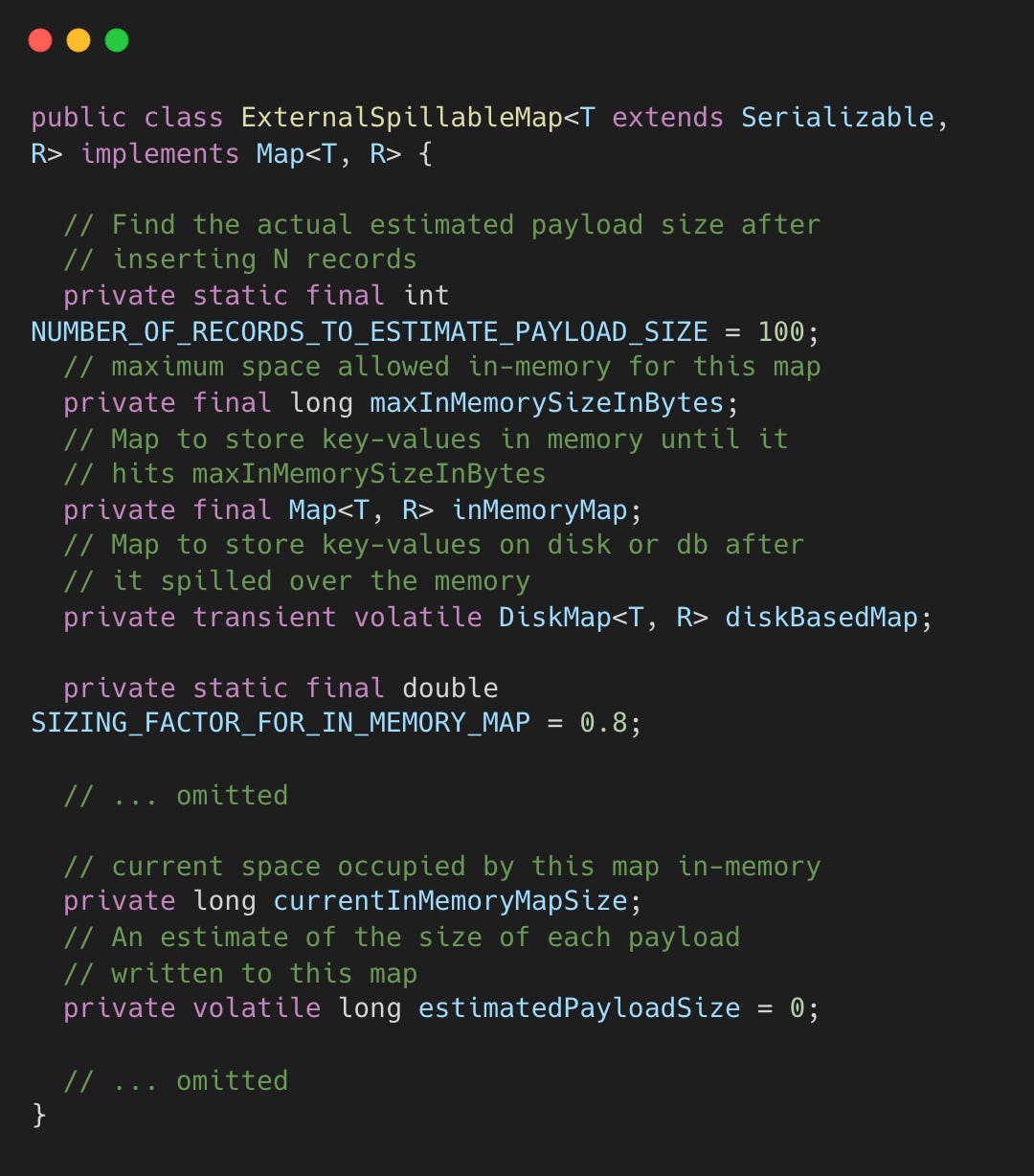
It reserves 20% of maxInMemorySizeInBytes (defined by SIZING_FACTOR_FOR_IN_MEMORY_MAP) for JVM overhead. A 1GB configuration starts spilling at 800MB.
Put Operation: Spillage Decision
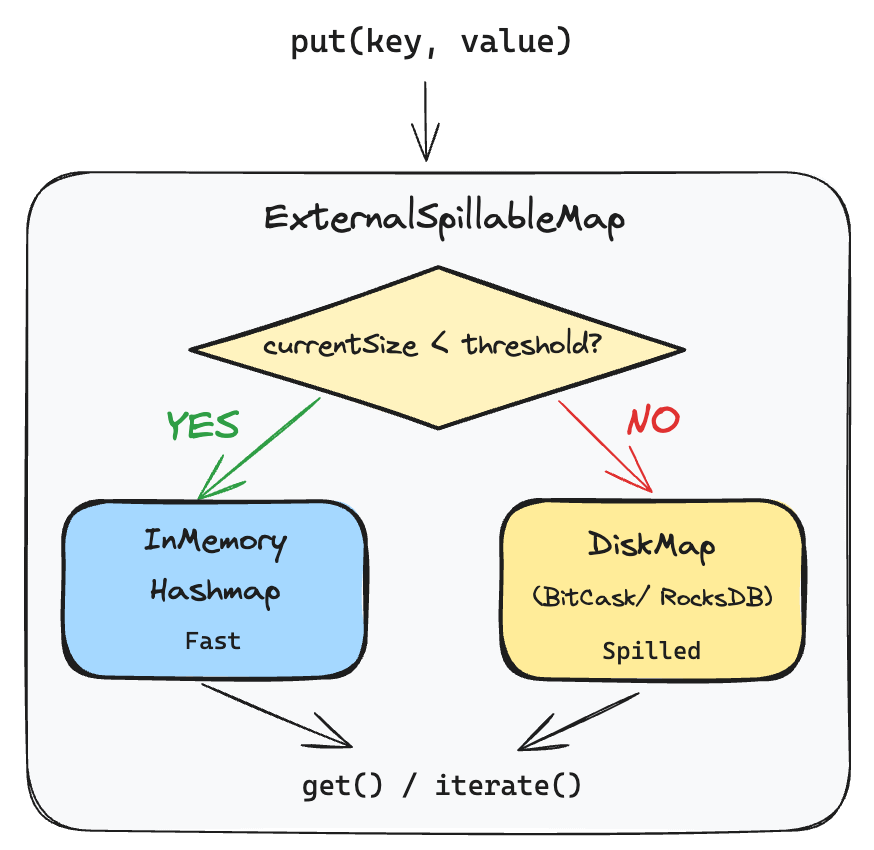
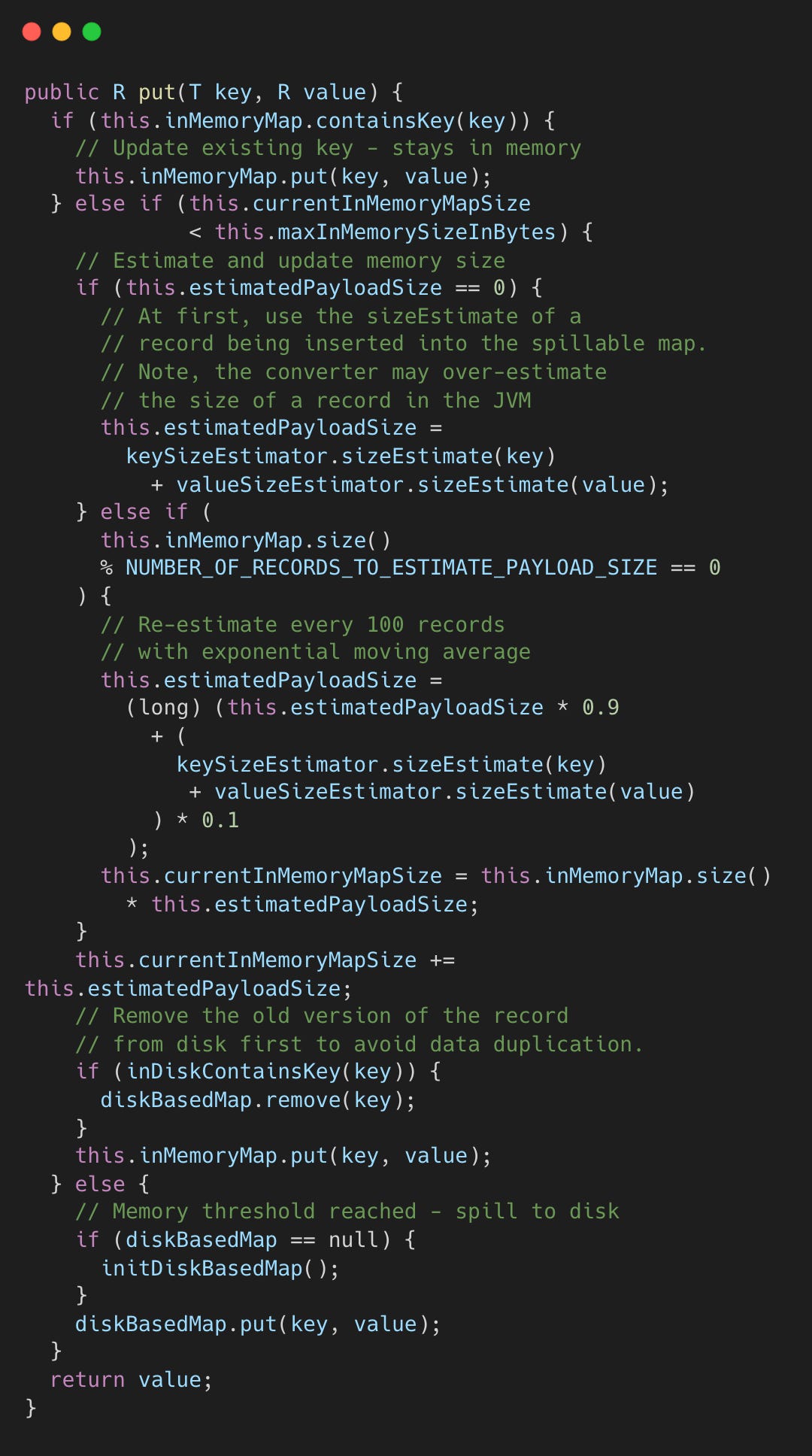
put() routes records to memory or disk based on usage.
ExternalSpillableMap.java#L218-L248
The flowchart below visualizes this logic.
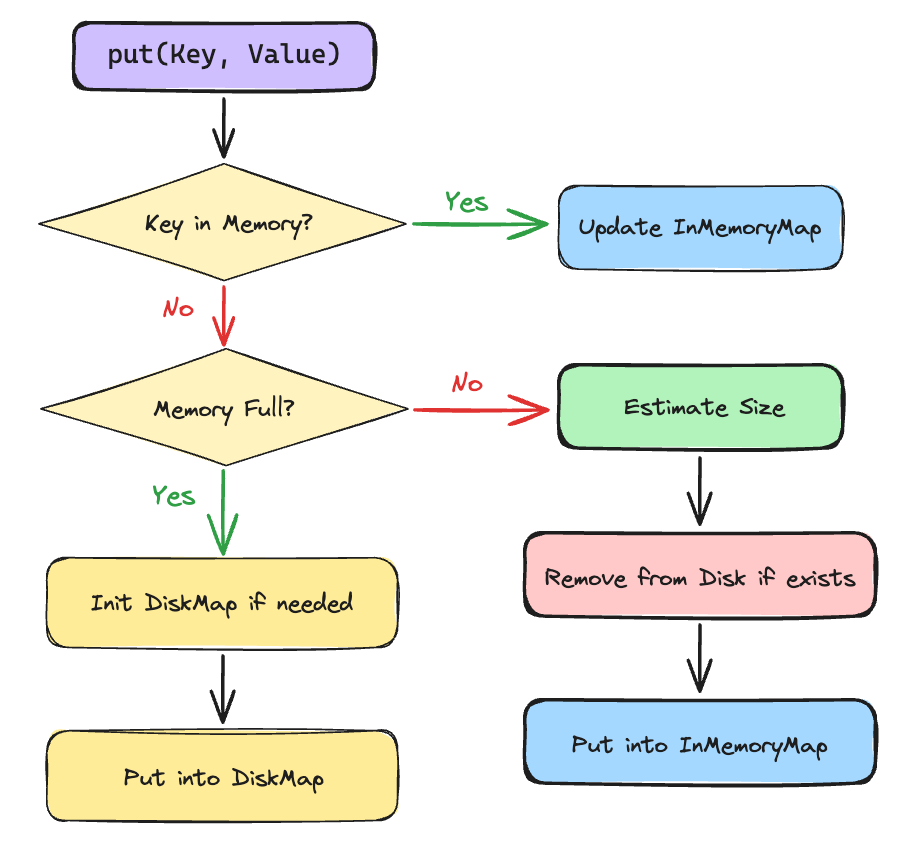
Three scenarios are:
Key in memory: Update in place.
Under threshold: Estimate size, add to memory, remove from disk if previously spilled.
Over threshold: Lazily initialize disk map, write to disk.
Get and Iterator Operations
get() and iteration hide storage details. get() checks memory first, then disk.
ExternalSpillableMap.java#L208-L216

Iteration provides a unified view, exhausting in-memory records before switching to disk.
ExternalSpillableMap.java#L132-L135

Consumers iterate without awareness of the data’s location.
Adaptive Size Estimation
Hudi estimates record size using an exponential moving average, recalculating every 100 records.
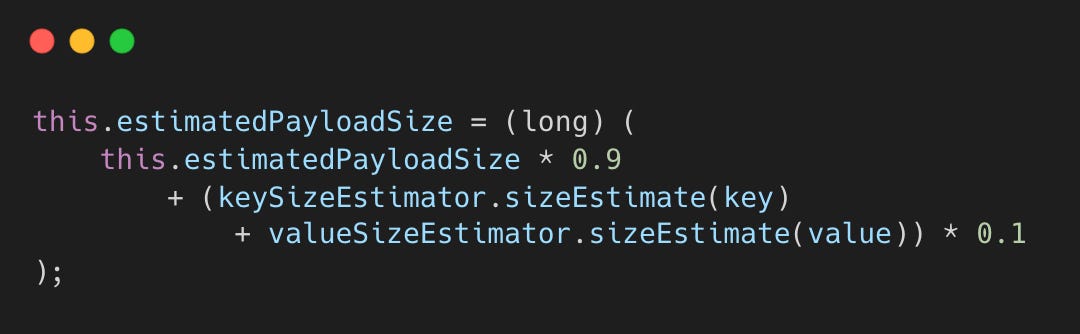
A 90/10 weighting prioritizes recent record sizes. This adaptive approach prevents premature spilling or OOM errors without manual tuning.
Two Disk Backends: BitCask and RocksDB
Spilled records use either BitCask or RocksDB, configured via hoodie.common.spillable.diskmap.type.
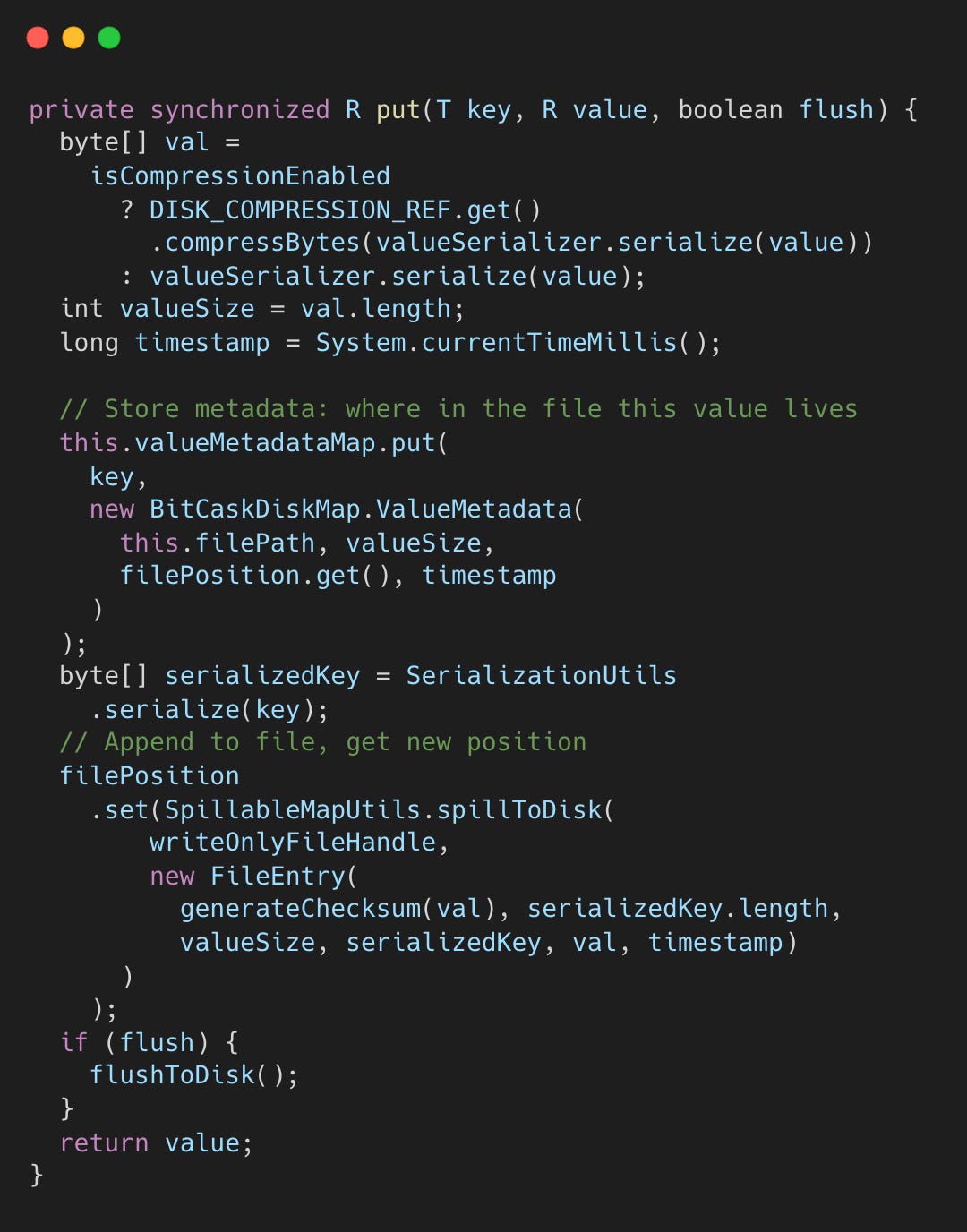
BitCask: Append-Only
A simple append-only file with an in-memory offset map.
The diagram below shows how entries are laid out on disk.
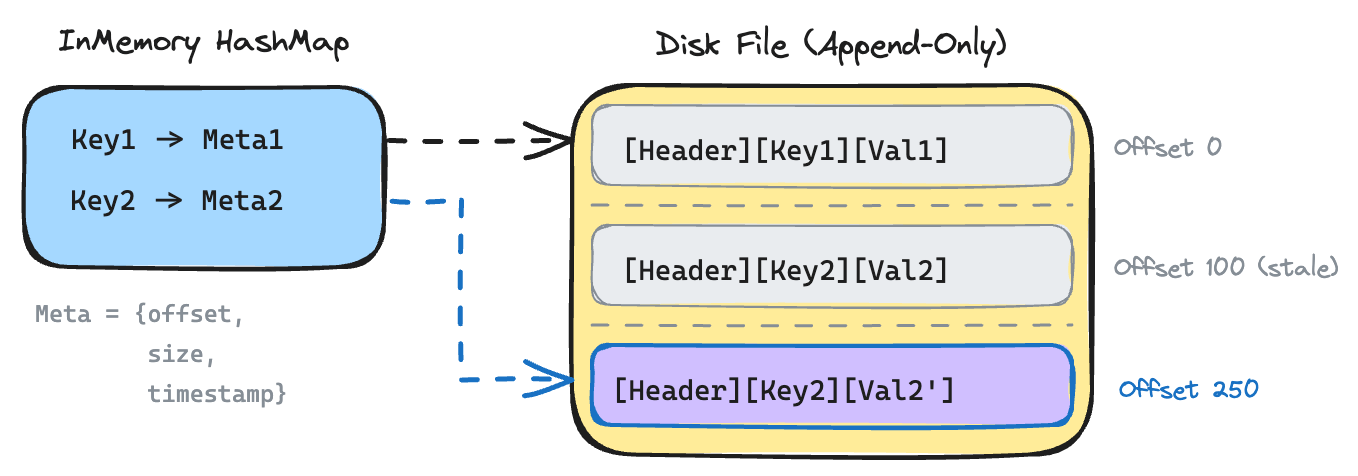
Reads seek directly using RandomAccessFile.
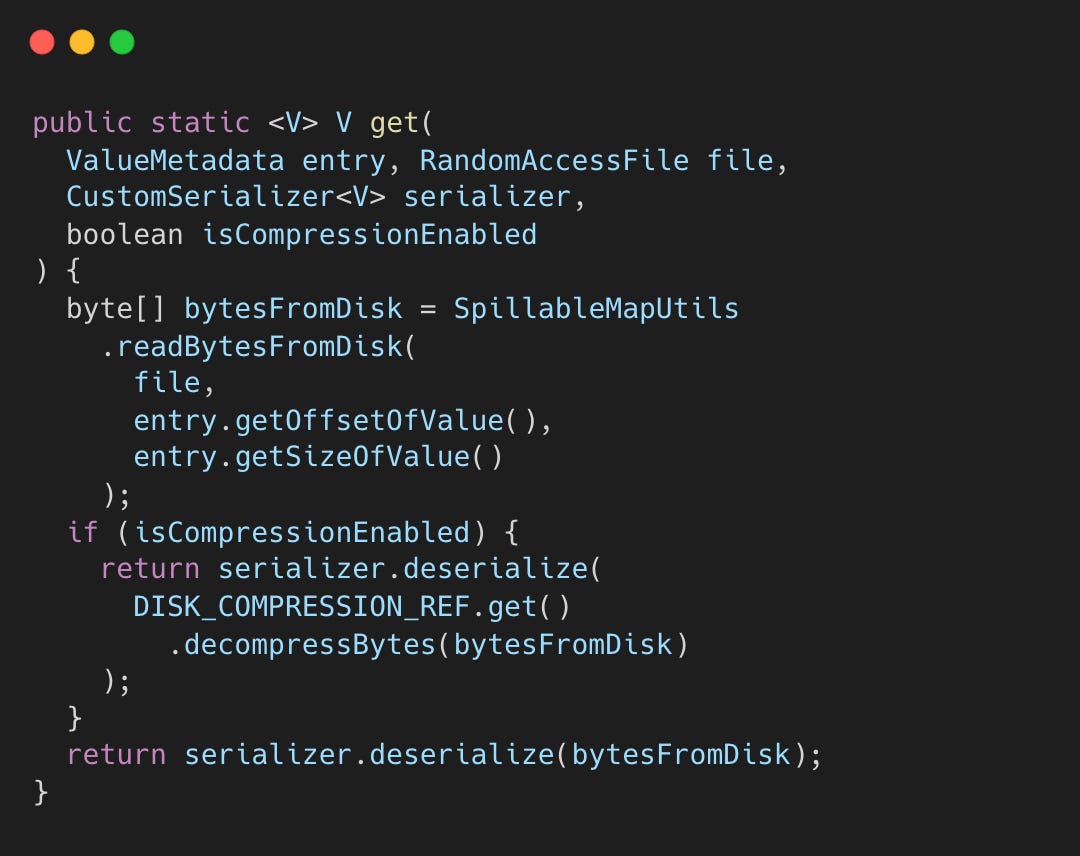
RocksDB: LSM-Tree
RocksDbDiskMap uses RocksDB, an LSM-tree store optimized for writes.

RocksDB handles compaction and off-heap memory, scaling better for large datasets. Unlike BitCask which keeps all keys in memory (the offset map), RocksDB stores keys on disk in SSTables, so it can handle key sets larger than RAM.
Usage: HoodieMergedLogRecordScanner
HoodieMergedLogRecordScanner uses ExternalSpillableMap to merge records during compaction and queries.
Initialization
The scanner initializes the map with memory limits and backend settings.
HoodieMergedLogRecordScanner.java#L120-L123

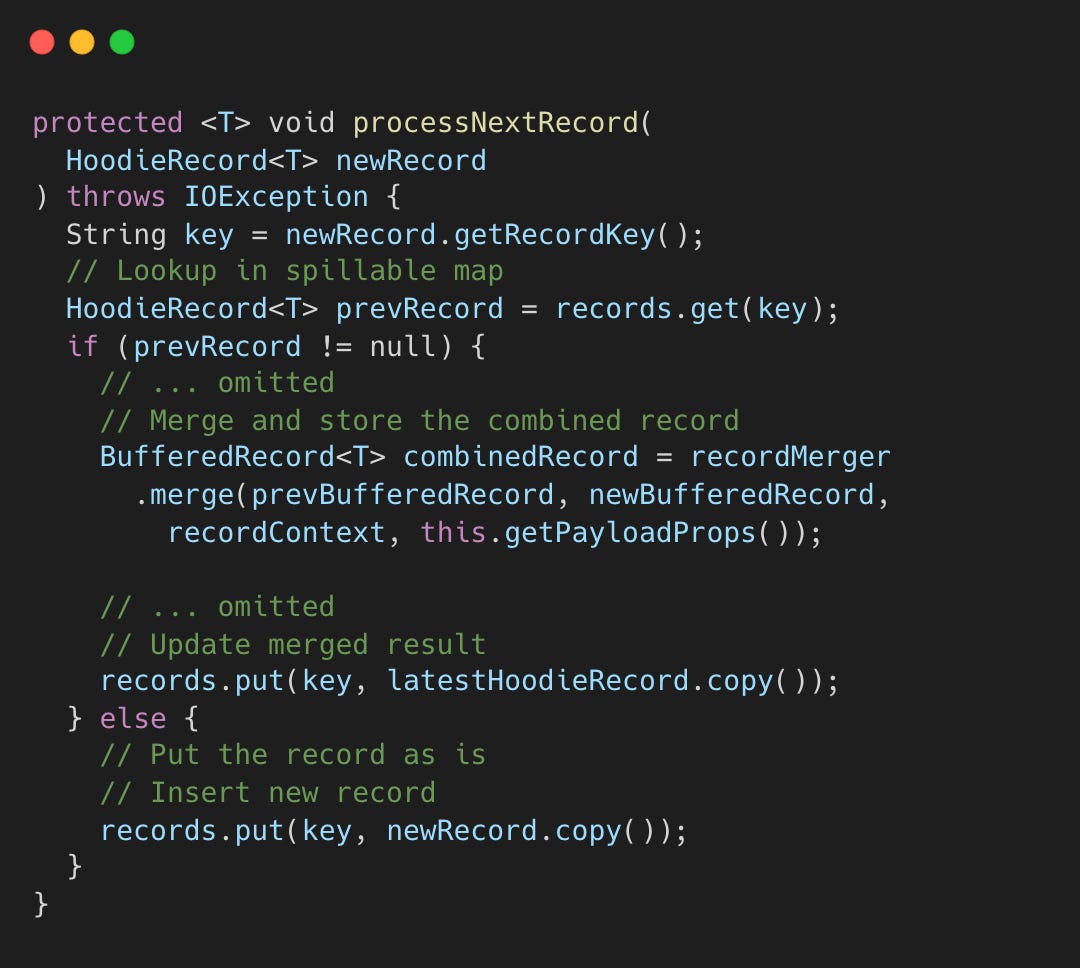
Processing Records
processNextRecord() merges duplicates. ExternalSpillableMap handles storage transparently.
HoodieMergedLogRecordScanner.java#L255-L281
Iteration and Statistics
The scanner also logs useful diagnostics.
HoodieMergedLogRecordScanner.java#L224-L227
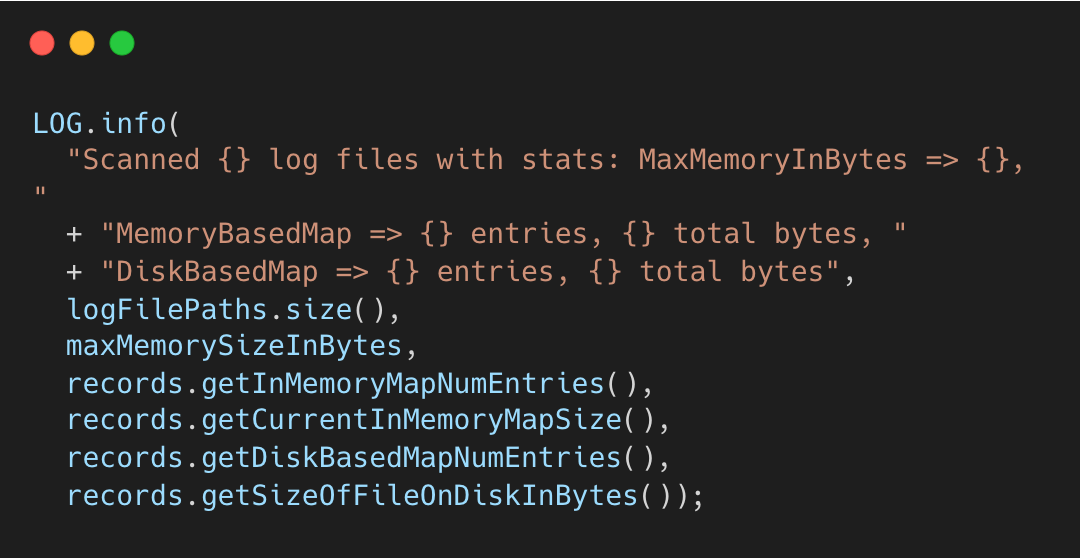
If the number of entries are high, increasing hoodie.memory.merge.fraction can reduce spill.
Other Uses
SpillableMapBasedFileSystemView: Caches file group metadata for the table’s file system view.HoodieCDCLogger: Buffers CDC records.
Major Contributions
PR #289 Added support for Disk Spillable Compaction to prevent OOM issues by @n3nash (Nishith Agarwal)
PR #3194 [HUDI-2028] Implement RockDbBasedMap as an alternate to DiskBasedMap by @rmahindra123 (Rajesh Mahindra)
Please let me know if I missed any other major contributors!