
[ClickHouse] Row Order Optimizer: Compression Hidden in Your Sort Key
Performance · Reordering rows within equal ranges for better compression

ClickHouse is an open-source columnar database built for real-time analytics over billions of rows. Its MergeTree engine stores data sorted by sort key for fast scans and efficient compression. But within rows sharing identical sort key values, the order is arbitrary, leaving compression gains on the table.
The optimize_row_order setting fixes this by reordering non-key columns to maximize compression, based on an insight from Daniel Lemire and Owen Kaser’s 2011 paper: sort by increasing cardinality.
What is MergeTree?
MergeTree is ClickHouse’s principal table engine. It stores data in columnar format, separate on disk. A query like SELECT avg(value) FROM events reads only the value column, making analytics fast.
The ORDER BY in a MergeTree definition controls physical storage. Rows are sorted by these columns upon insert and maintained during background merges.
This physical sorting provides two key advantages.
Fast Lookups: ClickHouse can use binary search on sorted primary keys.
Better Compression: Similar values cluster together, making them easier to compress.
Data arrives in parts (batches), and ClickHouse periodically merges smaller parts into larger ones, hence “MergeTree.” Each merge re-sorts and re-compresses the data.
The row order optimizer exploits a gap in this design: within rows that have identical sort key values, the order is arbitrary. That’s where free compression gains hide.
Key Patterns
A few patterns in MergeTree’s implementation to note are as follows.
LSM-Tree-Like Background Merges - Parts are periodically merged in the background.
MergeTreeDataMergerMutator.cpp#L391-L434

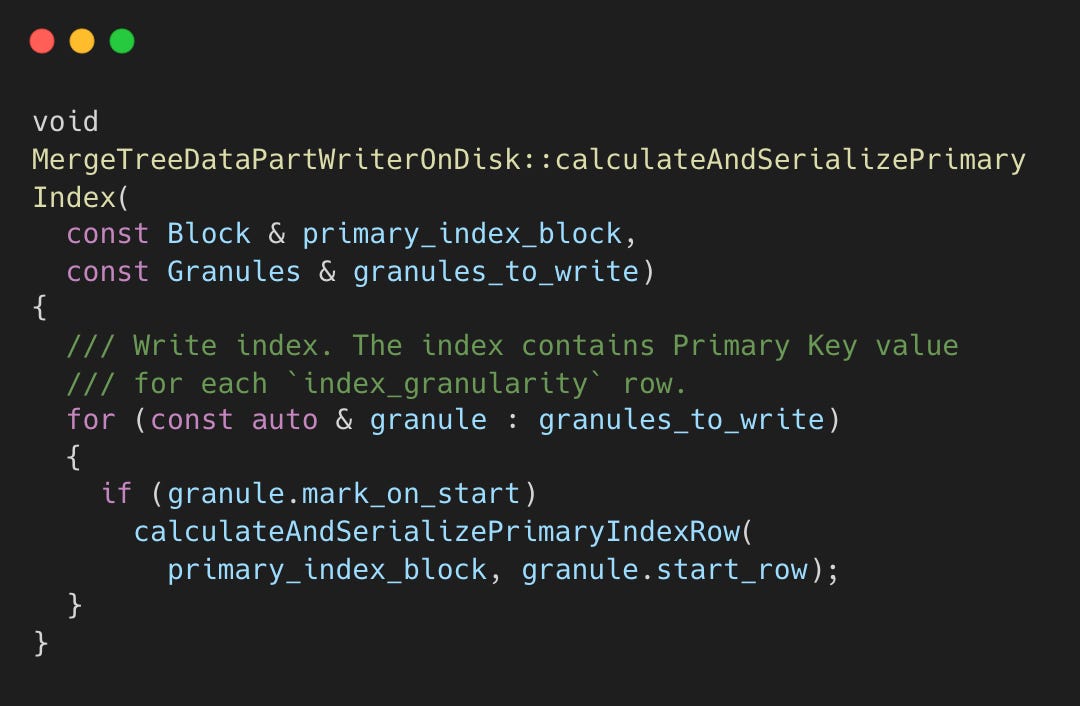
Sparse Primary Index - Instead of indexing every row, MergeTree stores one index entry per index_granularity rows.
MergeTreeDataPartWriterOnDisk.cpp#L203-L233
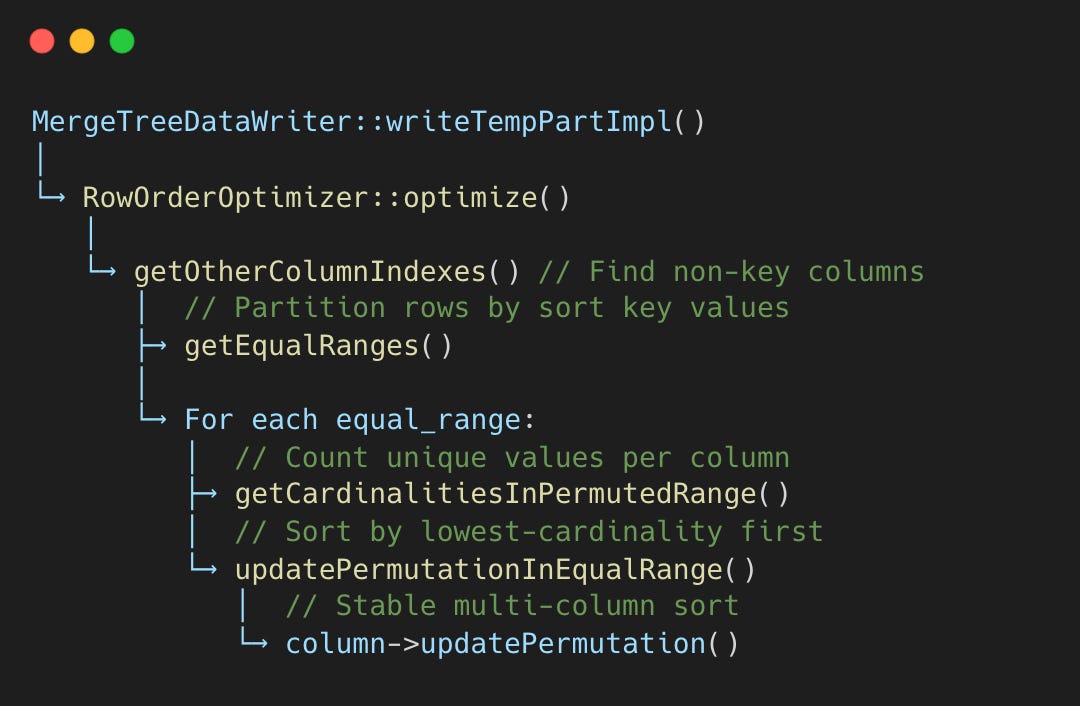
Row Order Optimizer Algorithm
On insert, ClickHouse sorts rows by sort key and creates equal ranges, groups with identical sort key values. Within these ranges, rows can be reordered without breaking the sort key contract. The Row Order Optimizer exploits this freedom.
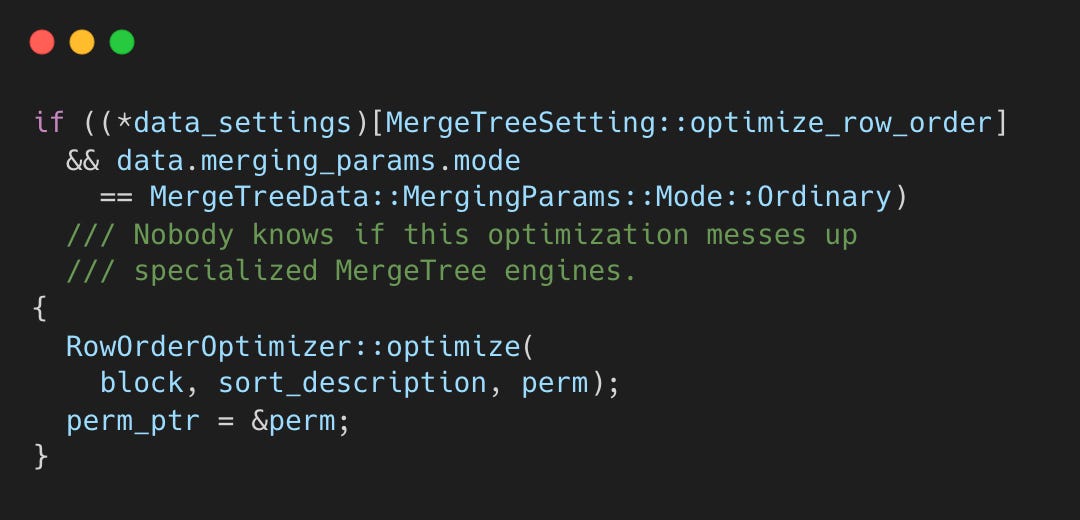
The optimization runs for ordinary MergeTree tables but not for specialized engines like ReplacingMergeTree or AggregatingMergeTree where row semantics matter.
Entry Point
When data is inserted, writeTempPartImpl() checks if row order optimization is enabled.
MergeTreeDataWriter.cpp#L769-L775
The optimize() function orchestrates the entire process.
RowOrderOptimizer.cpp#L153-L186
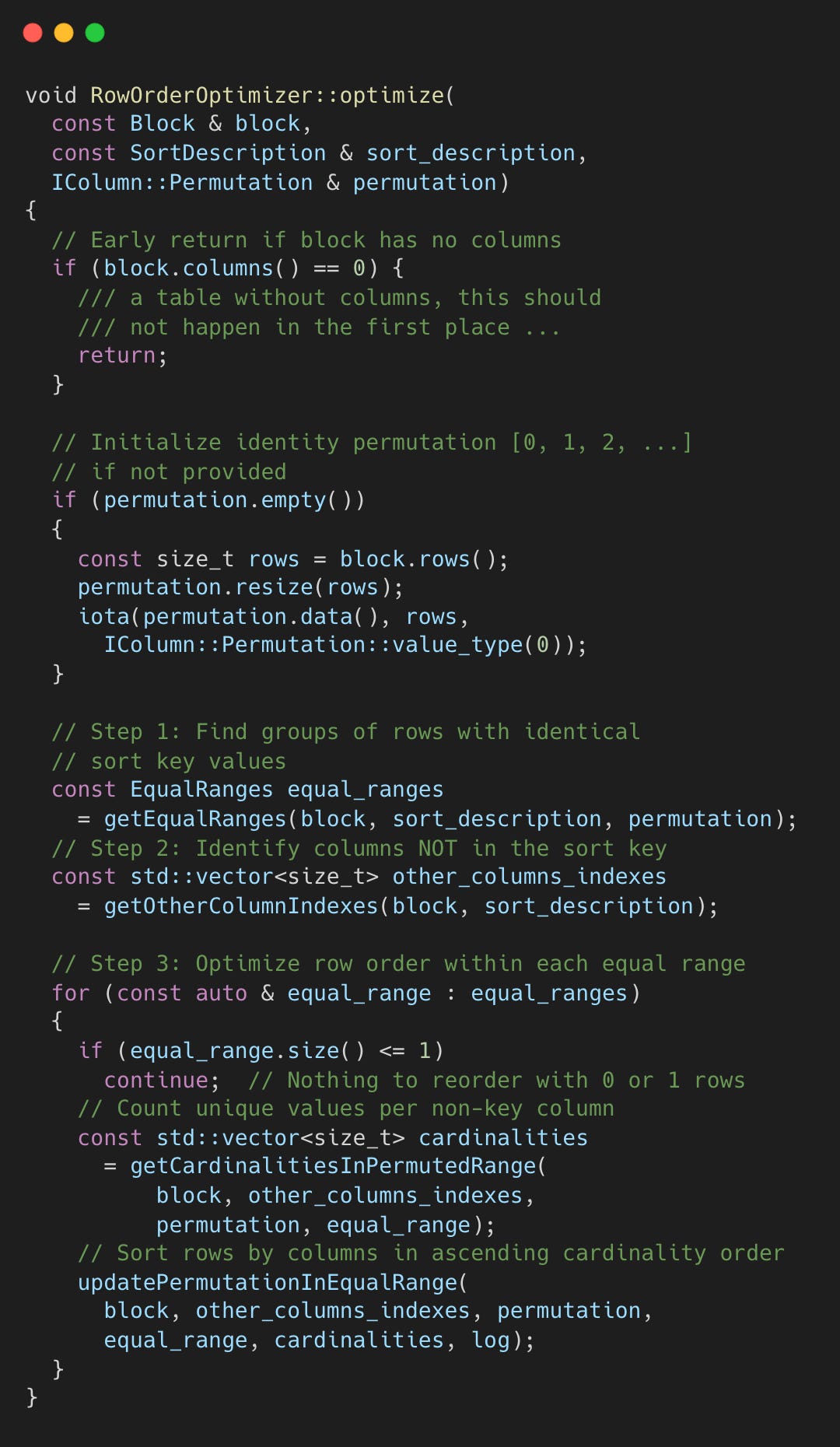
getOtherColumnIndexes() — Find Non-Key Columns
This function identifies columns not in the sort key. These are columns we’re free to reorder by.
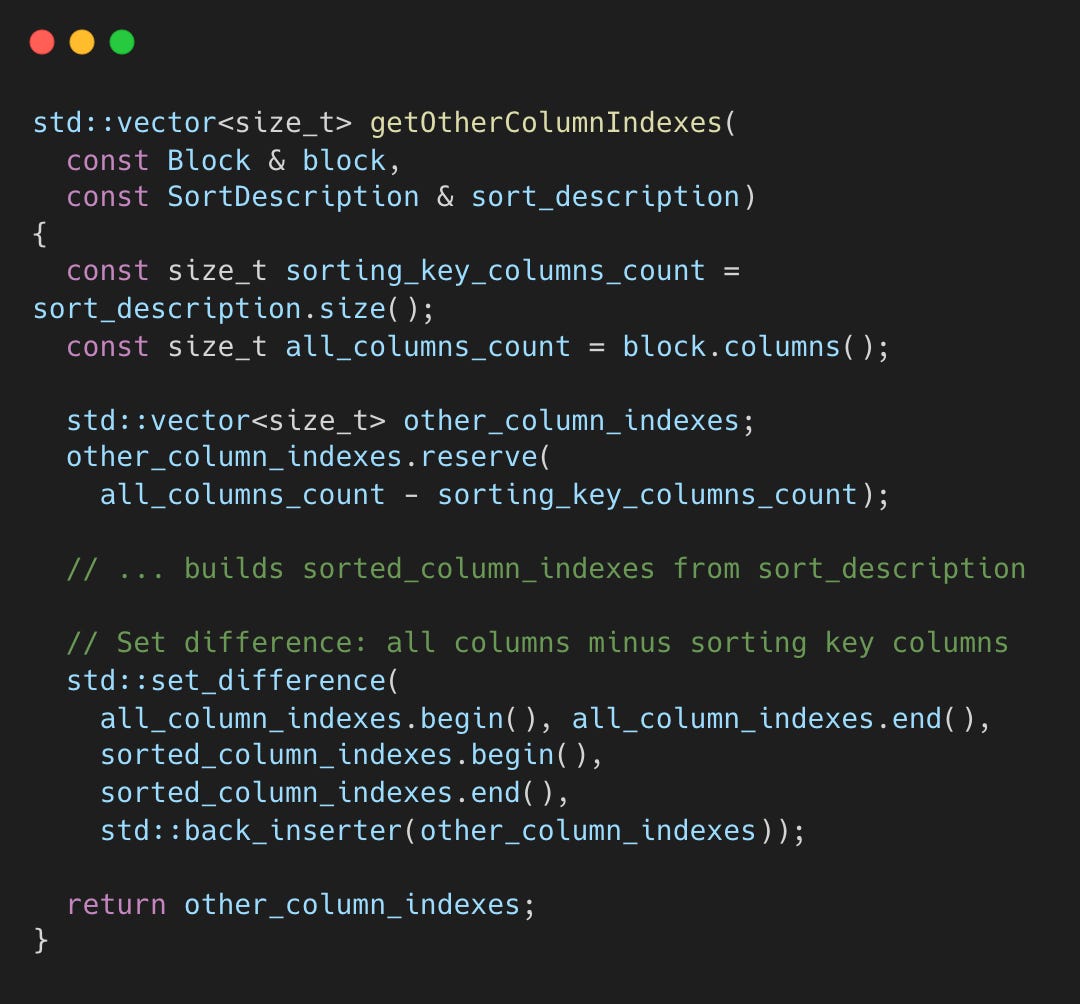
getEqualRanges() — Partition by Sort Key
Rows are partitioned into groups where all sort key columns have identical values.
RowOrderOptimizer.cpp#L84-L104
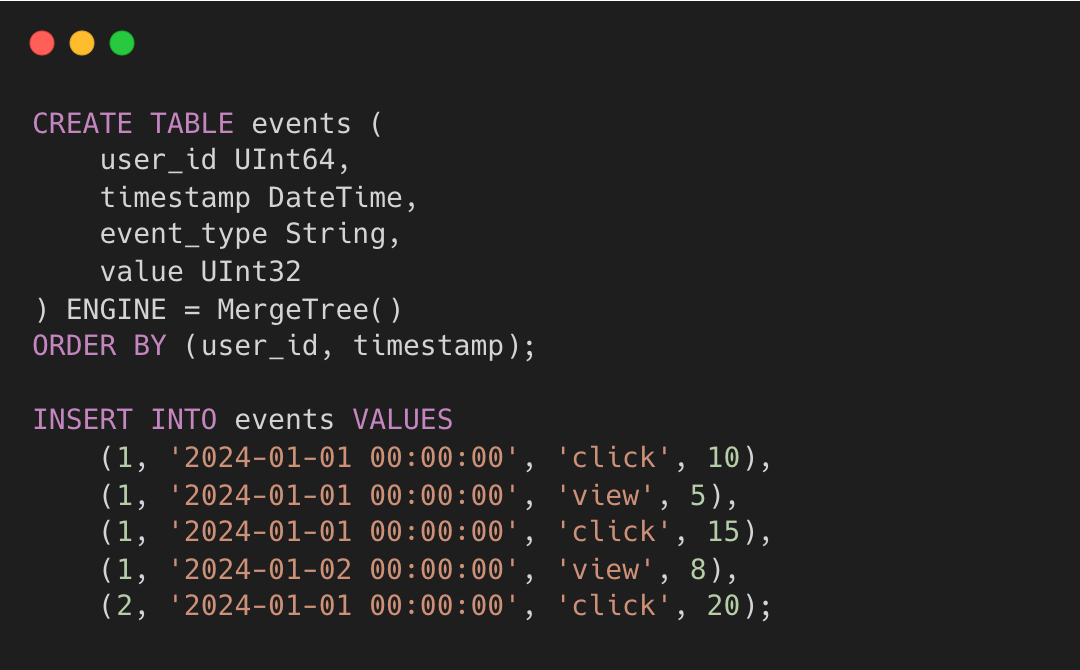
Consider a table with sort key (user_id, date) and columns (event_type, value). If you insert
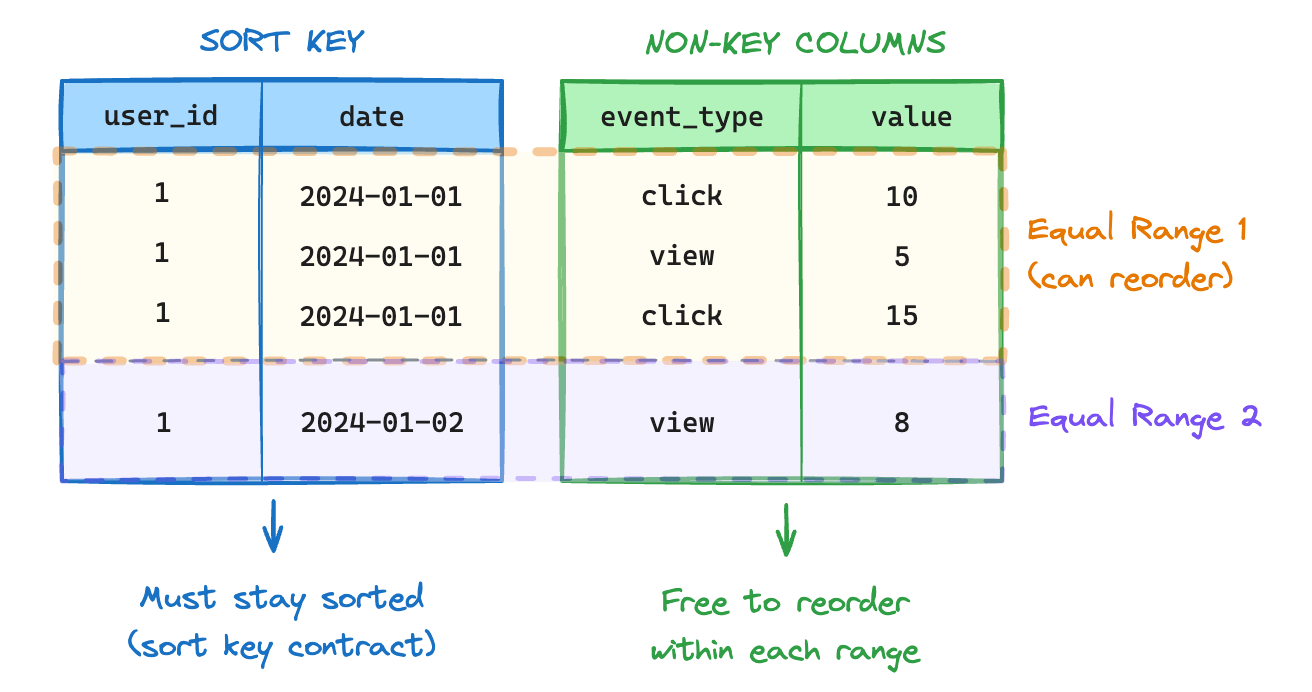
Rows 1-3 form one equal range (same user_id=1, date=2024-01-01). Row 4 is its own range.
getCardinalitiesInPermutedRange() — Count Unique Values
For each non-key column, estimate how many unique values exist within the equal range.
RowOrderOptimizer.cpp#L106-L120
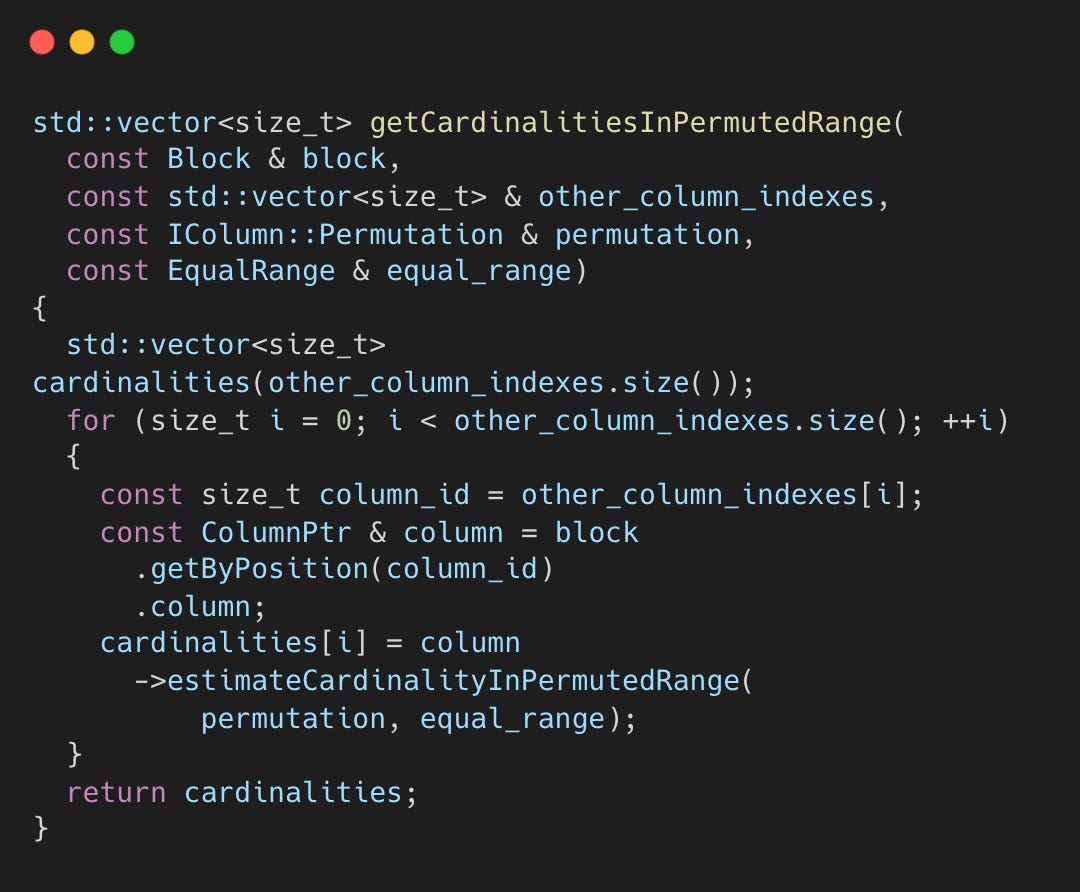
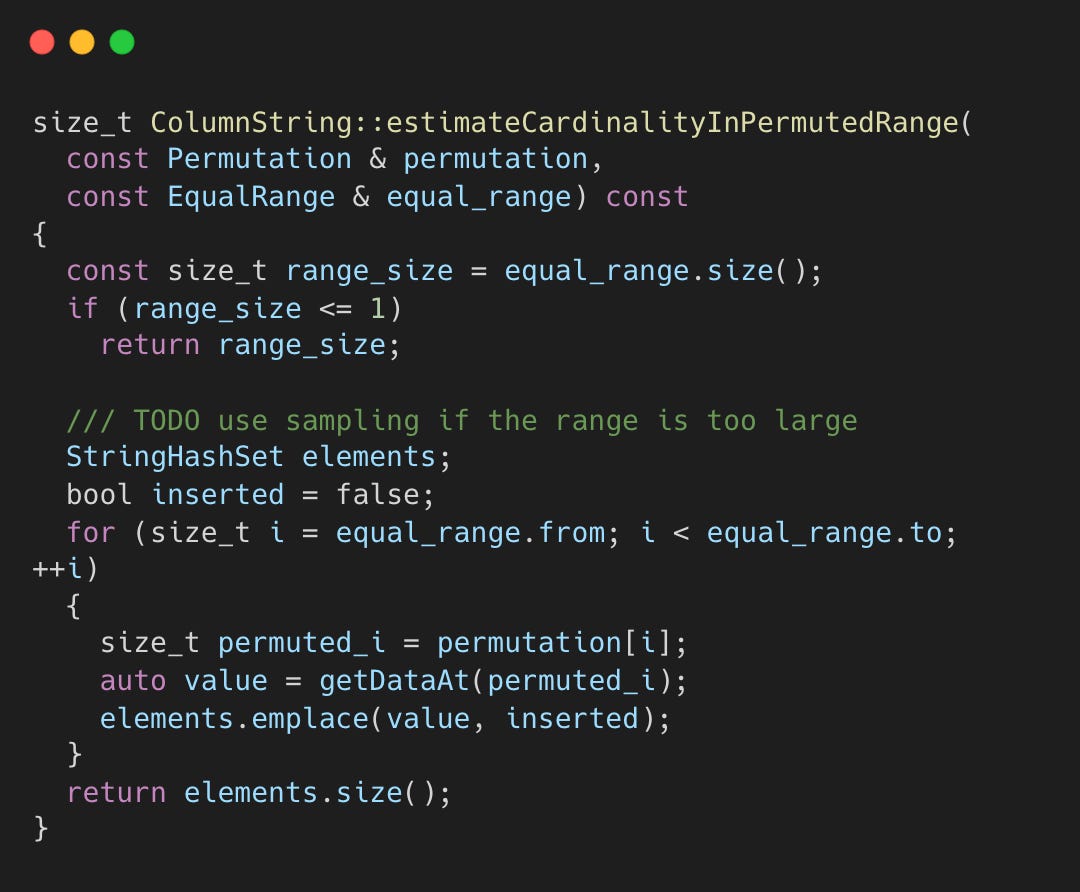
Each column type implements estimateCardinalityInPermutedRange(). For strings, it inserts values into a hash set. Duplicates are ignored, so the set size is the cardinality.
updatePermutationInEqualRange() — Sort by Cardinality
Sort columns by ascending cardinality, then sort rows by those columns.
RowOrderOptimizer.cpp#L122-L149
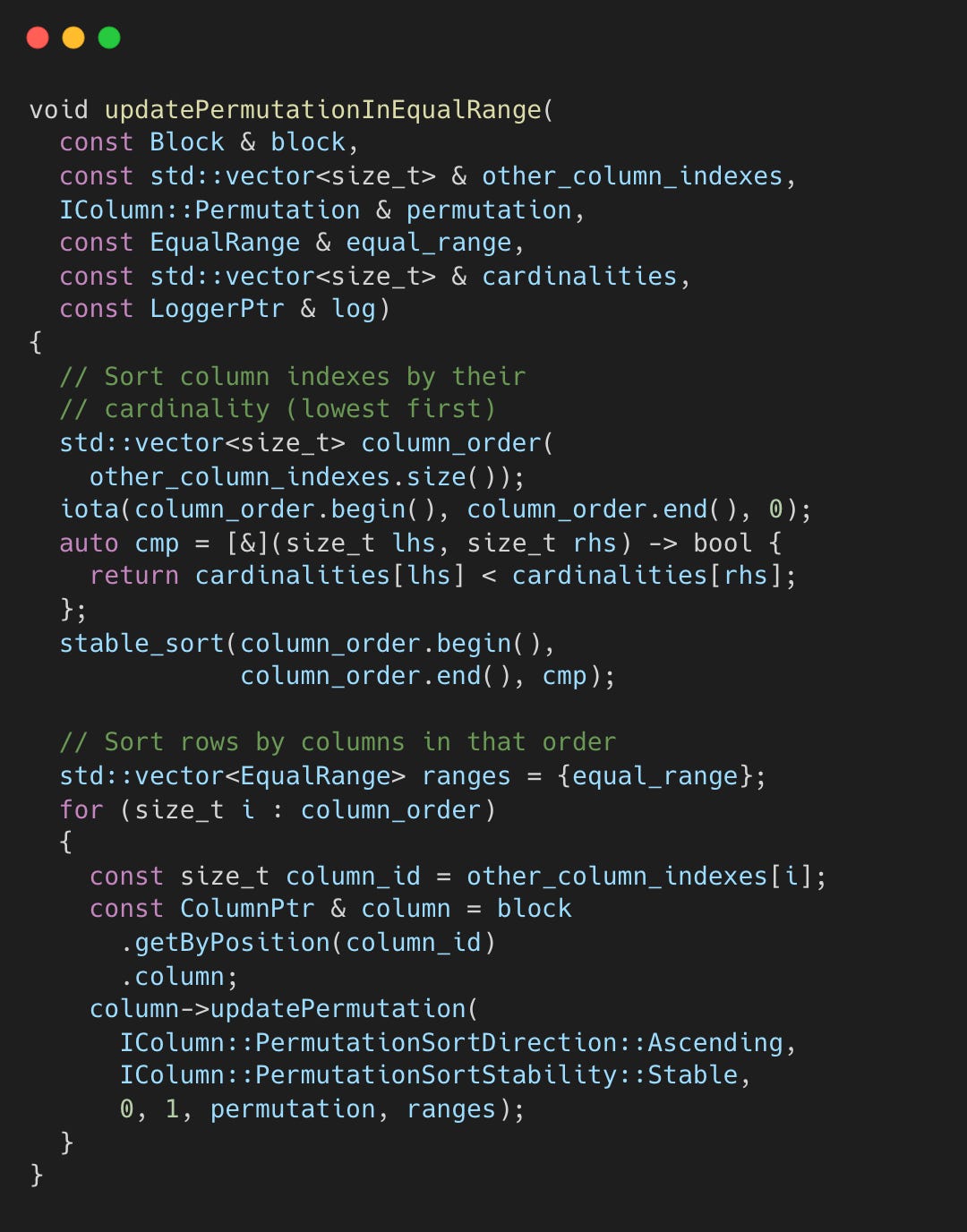
The ranges vector enables multi-column sorting. Each updatePermutation() call sorts rows within existing ranges and subdivides them where values are equal, so subsequent columns only sort within those sub-ranges.
The algorithm sorts rows by non-key columns in ascending cardinality order. If event_type has 2 unique values and value has 100, sorting by event_type groups identical values together. Longer runs of identical values yield better compression.
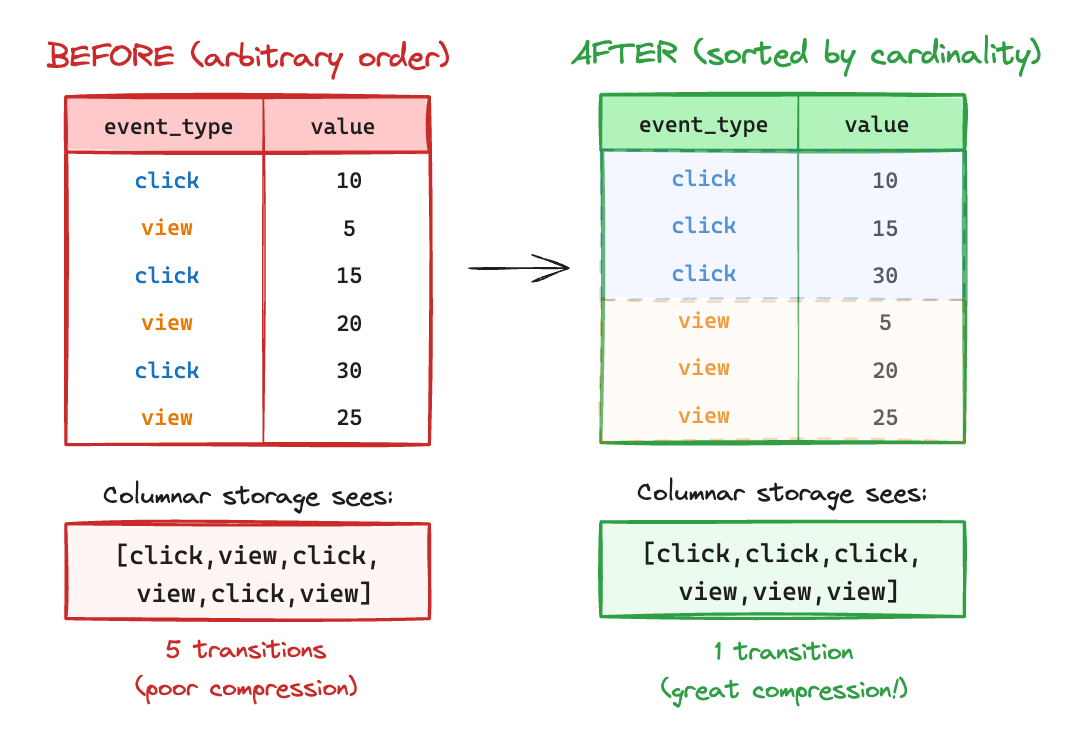
Since columnar databases store columns as contiguous arrays, clustered identical values allow algorithms to encode “repeat N times” rather than storing each value.
Major Contributions
PR #63578 Best-effort sorting to improve compressability by @ElderlyPassionFruit (Igor Markelov)
Please let me know if I missed any other major contributors to the Row Order Optimizer!