
Cutting LLM Token Costs with rtk, headroom, and caveman
Design · Internals, the limited savings measured on real workloads, and security risks

Three open-source projects promise to reduce the tokens your coding agent uses. rtk, headroom, and caveman all drew tens of thousands of GitHub stars and report 60 to 90 percent savings. This post is a deep dive into what each one actually does, tested on real workloads. Replayed over a 614M-token corpus of my own past Claude Code sessions, the three together saved 3.7 percent of spend, far below what they claim.
An agent turn moves tokens through three places. The model reads an input (system prompt, your message, prior tool results) and produces an output holding its prose and tool calls. Those tool calls run as commands whose tool output flows back into the next input. Each of the three projects works on one of these streams.
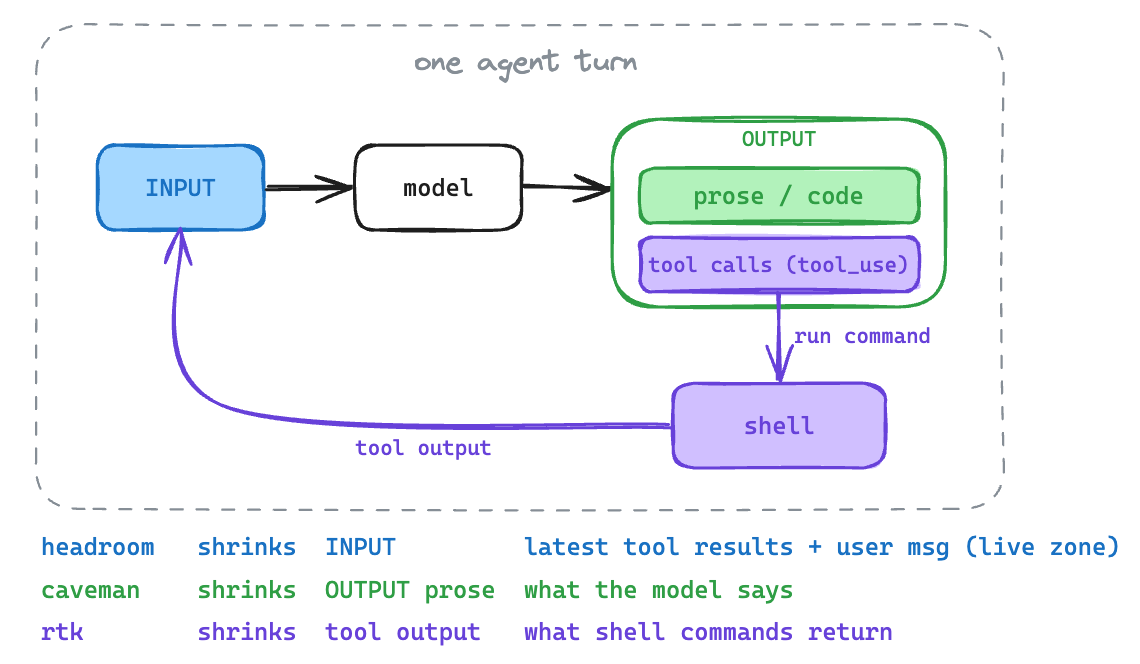
headroom: a proxy that compresses by content type
headroom is an API proxy. It sits between the agent and the provider once you point ANTHROPIC_BASE_URL at it or run headroom wrap claude, seeing every byte. The design centers on a live zone.
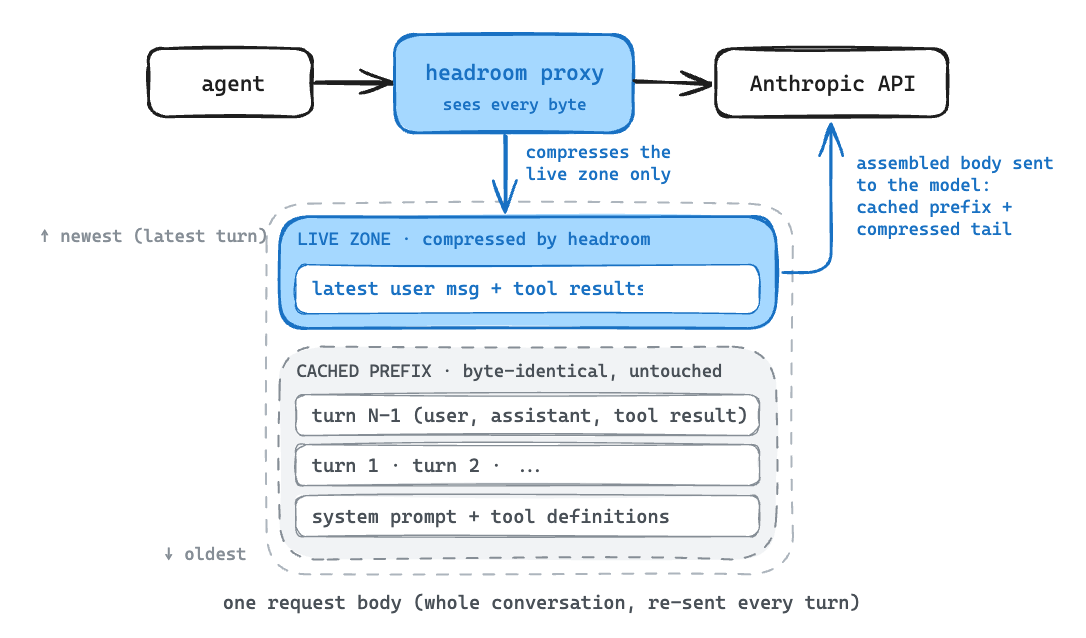
Every request splits in two. Everything up to the last cache marker is already stored in the provider’s KV-cache, while the newest user message and its tool results are not yet cached. That uncached tail is the live zone, the only part headroom is free to rewrite. It compresses those blocks while leaving the older messages unchanged, so the cached prefix still hits instead of breaking the cache and costing more than it saves.
Inside the live zone, a router sends each content block (one tool result or message part) to a specialist compressor by content type. The router recognizes seven types and maps each to a strategy.
mapping = {
ContentType.SOURCE_CODE: CompressionStrategy.CODE_AWARE,
ContentType.JSON_ARRAY: CompressionStrategy.SMART_CRUSHER,
ContentType.SEARCH_RESULTS: CompressionStrategy.SEARCH,
ContentType.BUILD_OUTPUT: CompressionStrategy.LOG,
ContentType.GIT_DIFF: CompressionStrategy.DIFF,
ContentType.HTML: CompressionStrategy.HTML,
ContentType.PLAIN_TEXT: CompressionStrategy.TEXT,
}Source code goes to an AST-aware CodeAware compressor, JSON to SmartCrusher, plain text to Kompress, and other formats like build logs, git diffs, and HTML each get their own compressor. headroom also ships a faster Rust proxy that compresses four formats natively (JSON, build output, search results, and git diffs) and leaves the rest uncompressed.
Let’s look at the search-results compression. A grep or ripgrep dump arrives as hundreds of file:line:content rows, many repeating the same match in slightly different spots. Compression here means removing rows, so the compressor only has to decide which rows to keep. The compressor parses each row, scores it, then keeps only the top-scoring subset. A line gets more points when it matches the active query or a caller-configured keyword, and more when it looks like an error, so the rows an agent is most likely to need score highest and are kept.
for word in context_words:
if word in content_lower:
score += 0.3
if self.config.boost_errors:
for i, pattern in enumerate(PRIORITY_PATTERNS_SEARCH):
if pattern.search(match.content):
score += 0.5 - (i * 0.1)
break # only one priority boost per line, matches Rust
for keyword in self.config.context_keywords:
if keyword.lower() in content_lower:
score += 0.4The error boost checks three pattern types in order, error first, then warning, then general importance, and stops at the first match so a line is boosted only once. This is how an error row can outscore a plain query match.
Scoring ranks the rows, but how many to keep is a separate decision. The compressor does not keep a fixed top-N. It counts how many genuinely distinct matches the dump holds and keeps that many.
# Tier 1: Fast path
if n <= 8:
return n
# Check for near-total redundancy
unique_count = count_unique_simhash(items)
if unique_count <= 3:
k = max(min_k, unique_count)
return min(k, effective_max)
# Tier 2: Kneedle on unique bigram coverage
curve = compute_unique_bigram_curve(items)
knee = find_knee(curve)First it groups near-duplicates with SimHash, so a thousand almost-identical rows count as only a few distinct ones. If those few already capture every distinct match, it stops. Otherwise it adds matches one at a time until new ones stop bringing new words, and keeps that many.
The compressor always keeps the first and last match in every file, so the agent sees the full range a search covered rather than only a high-scoring group in the middle. The matches it removes during compression are replaced with a [... and N more matches in file] marker that tells the agent how many were cut.
headroom can also restore what it dropped. Its CCR (Compress-Cache-Retrieve) caches the original uncompressed content under a content hash and injects a headroom_retrieve tool, so the model can pull back the full data on demand when a compressor dropped something it needs.
CCR_TOOL_NAME = "headroom_retrieve"The store holds the original for five minutes after caching. The compressed view and its marker stay in the conversation either way, so if the model requests a blob after that window, the retrieve call returns empty and it falls back to the compressed view or re-runs the search.
headroom also manages rtk for you. headroom wrap claude downloads the rtk binary and registers it as a Claude Code hook, so rtk shrinks shell output on the CLI side while the proxy compresses the request on the wire. The two act on different token streams, so one command saves on both.
rtk: a wrapper that compacts command output
rtk intercepts shell commands before they execute. A PreToolUse hook rewrites git status into rtk git status. The model believes it ran the original. On the rewrite path, rtk runs the real binary through std::process::Command with separate arguments, not through a shell, then filters the output. The filters keep only the relevant fields, group related lines, drop repeated lines, and truncate long output with a hint on how to recover the rest.
The ls filter is a clear example. It collapses a long directory listing into a compact tree with counts, and it returns the raw output when parsing fails.
Here is what that looks like on the rtk repo itself. Raw ls -la gives one row per entry with mode, owner, group, byte size, and date.
total 632
drwxr-xr-x@ 37 yongkyunlee staff 1184 Jun 16 17:17 .
drwxr-xr-x@ 7 yongkyunlee staff 224 Mar 11 18:28 .claude
-rw-r--r--@ 1 yongkyunlee staff 251 Jun 16 17:17 .gitattributes
-rw-r--r--@ 1 yongkyunlee staff 98561 Jun 16 17:17 CHANGELOG.md
-rw-r--r--@ 1 yongkyunlee staff 7406 Jun 16 17:17 CLAUDE.md
(33 more rows in the same shape)rtk ls drops the columns the agent rarely needs, lists directories first with a trailing slash, shows file sizes in human units, and ends with a one-line summary. It also filters noise directories like .git and target unless -a is passed.
.claude/
docs/
src/
tests/
CHANGELOG.md 96.3K
CLAUDE.md 7.2K
README.md 21.2K
(rest of the files)
Summary: 23 files, 10 dirs (13 .md, 2 .json, 1 .toml, 1 .yml, 1 .gitignore, +5 more)let (entries, summary, parsed_count) = compact_ls(raw, show_all, show_long);
// If no lines were parsed (e.g., unrecognized locale), fall back to raw output.
// This is safer than returning "(empty)" for a non-empty directory.
let has_real_content = raw
.lines()
.any(|l| !l.starts_with("total ") && !l.is_empty() && !is_dotdir(l));
if parsed_count == 0 && has_real_content {
return raw.to_string();
}That fallback block is rtk‘s whole safety design. When a filter cannot parse the output, it passes the raw command through unchanged. A truncated diff includes a [full diff: rtk git diff --no-compact] hint so the agent can recover the dropped lines. rtk drops data only for the commands it knows how to filter. Anything else runs raw. It has one limitation. Claude Code’s built-in Read, Grep, and Glob calls never go through the Bash hook, so rtk only saves on what the agent runs in a shell.
caveman: hooks that make the model say less
caveman never transforms a payload at runtime. It rewrites the agent’s behavior with prompt injection through two hooks. A SessionStart hook reads its SKILL.md ruleset, filters it down to the active intensity level, and pastes it in as hidden system context before turn one.
// Read SKILL.md — the single source of truth for caveman behavior.
// Plugin installs: __dirname = <plugin_root>/hooks/, SKILL.md at <plugin_root>/skills/caveman/SKILL.md
// Standalone installs: __dirname = $CLAUDE_CONFIG_DIR/hooks/, SKILL.md won't exist — falls back to hardcoded rules.
let skillContent = '';
try {
skillContent = fs.readFileSync(
path.join(__dirname, '..', 'skills', 'caveman', 'SKILL.md'), 'utf8'
);
} catch (e) { /* standalone install — will use fallback below */ }A second hook runs on the UserPromptSubmit event, which fires every time you send a message, and re-injects the same rules. It is needed because the first injection does not always last. As the conversation grows, Claude Code compresses old context to save space and other plugins add their own text. Either one can push the original rules out of the window, and once they are gone the model drifts back to its wordy default.
caveman-mode-tracker.js:124-131
process.stdout.write(JSON.stringify({
hookSpecificOutput: {
hookEventName: "UserPromptSubmit",
additionalContext: "CAVEMAN MODE ACTIVE (" + activeMode + "). " +
"Drop articles/filler/pleasantries/hedging. Fragments OK. " +
"Code/commits/security: write normal."
}
}));This reminder stays small, a one-line note rather than the full ruleset, which still comes from the session-start injection.
The ruleset drops articles, filler, pleasantries, and hedging, allows fragments, and prefers short synonyms (”big” not “extensive”). It keeps technical terms, code blocks, file paths, API names, and error strings exact.
Pattern: `[thing] [action] [reason]. [next step].`
Not: "Sure! I'd be happy to help you with that. The issue you're experiencing is likely caused by..."
Yes: "Bug in auth middleware. Token expiry check use `<` not `<=`. Fix:"An intensity level controls how far this goes. full is the default. lite keeps full sentences and cuts only filler. ultra abbreviates prose words like config and req and uses arrows for cause and effect, but never touches real code symbols. There are also wenyan levels that compress into classical Chinese for more savings.
Example — "Why React component re-render?"
- lite: "Your component re-renders because you create a new object reference each render. Wrap it in `useMemo`."
- full: "New object ref each render. Inline object prop = new ref = re-render. Wrap in `useMemo`."
- ultra: "Inline obj prop → new ref → re-render. `useMemo`."caveman turns off the terse style and writes full sentences for security warnings, irreversible action confirmations, and ordered multi-step sequences. This rule outranks every compression rule above it, so terseness never wins when a dropped word could cause real harm.
caveman reduces output tokens only, never thinking tokens. The project sums it up as “Brain still big. Mouth small.” Its advertised 65 percent average is measured against a verbose “helpful assistant” default, so it includes the savings any terse instruction would give. Measured over a plain “Answer concisely.” baseline, the honest delta is lower. Our own microbenchmark below lands at 50 percent median.
Our measurements on real workloads
Measuring each tool directly
We measured each transform directly instead of through a live agent. In a live run the token difference between configurations comes mostly from turn count, which varies run to run and hides whatever the compressor did. On a fixed payload the result is deterministic.
We captured payloads from four frozen open-source checkouts, VS Code 1.99, llama.cpp b9692, uv 0.11.21, and ollama 0.30.10. In each repo we grepped one high-frequency symbol so the search returned thousands of near-identical match lines, registerSingleton in VS Code, ggml_tensor in llama.cpp, every pub fn in uv, and every func in ollama. For git diff we took one real release-to-release range over a representative subdirectory, the chat browser code from 1.98 to 1.99, ggml/src from b9500 to b9692, the uv-resolver crate from 0.10 to 0.11.21, and server/ from v0.30.0 to v0.30.10. Each tool then ran over the stream it owns: headroom over tool-result input, rtk over shell output, and caveman over model prose.
headroom ran over those diffs and grep dumps. Its grep result swings the widest, from 99 percent on repetitive matches down to 10 percent when the matches are already distinct.

rtk ran four shell commands in each repo, the same grep and git diff plus ls -la on a large directory (src/vs/workbench/contrib/, ggml/src/, crates/, server/) and git log --stat -50. grep cuts the most, because rtk returns a grouped count instead of every matching line. rg registerSingleton across VS Code's src/ went from 694k tokens to 2.4k.
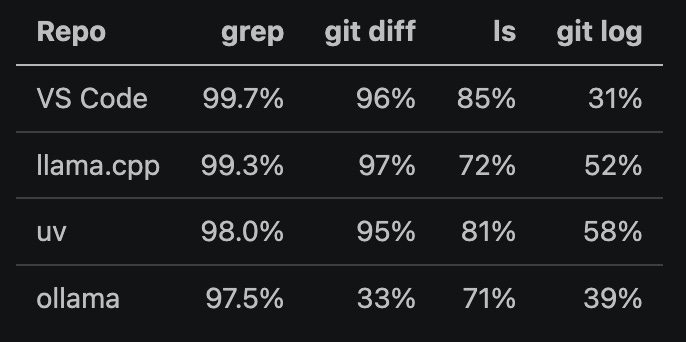
grep stays near 99 percent in every repo because near-identical match lines collapse well. ollama is the outlier on git diff. Its change from v0.30.0 to v0.30.10 over server/ was small and code-dense, so rtk cut only 33 percent.
caveman ran over its ten prose eval prompts. Each prompt’s answer with the skill is measured against the same prompt answered under a plain Answer concisely. system prompt with no skill. caveman‘s own evals use this terse control rather than a verbose default, so the savings reflect what the skill adds on top of just asking for a short answer.

The smallest cut was the memory-leak answer at 0.4 percent, because it was already terse. The median across the ten was 50 percent.
Each tool reaches its advertised savings on the content built for it. headroom‘s median across grep and diff is 54 percent, rtk cuts recognized shell output 33 to 99 percent, and caveman halves prose. These numbers are real and reproducible, but they measure one stream in isolation on ideal input.
Replay over real sessions
A best-case number is not a real bill, so the second experiment replays each tool over real traffic. The traffic is my own Claude Code history under ~/.claude/projects, 2,182 sessions across 13 project directories. We sampled 500 of them, stratified across the directories so no single project dominates. Empty sessions and one runaway outlier were dropped. Together the 500 sessions are a 614M-token corpus carrying $926.31 of baseline spend, and we recomputed each tool’s counterfactual turn by turn.
headroom is measured directly. Its compressor is a pure function of the payload, so we ran the real compressor on every recorded tool-result. rtk and caveman cannot be replayed faithfully on historical logs, so both are estimated. rtk applies its own published per-command savings rates (what-rtk-covers.md:12-20, 60 to 99 percent depending on the command) to the real token size of every recorded shell output it would have matched. caveman cannot be replayed at all, since it is a prompt that shortens the model’s writing as it generates, not something you can run on finished text. So for each recorded answer we count its prose tokens, excluding code blocks the way the skill does, and multiply by caveman‘s median prose reduction of about 50 percent. That assumes caveman shortens real answers at the benchmark rate, which makes it the softest estimate of the three.
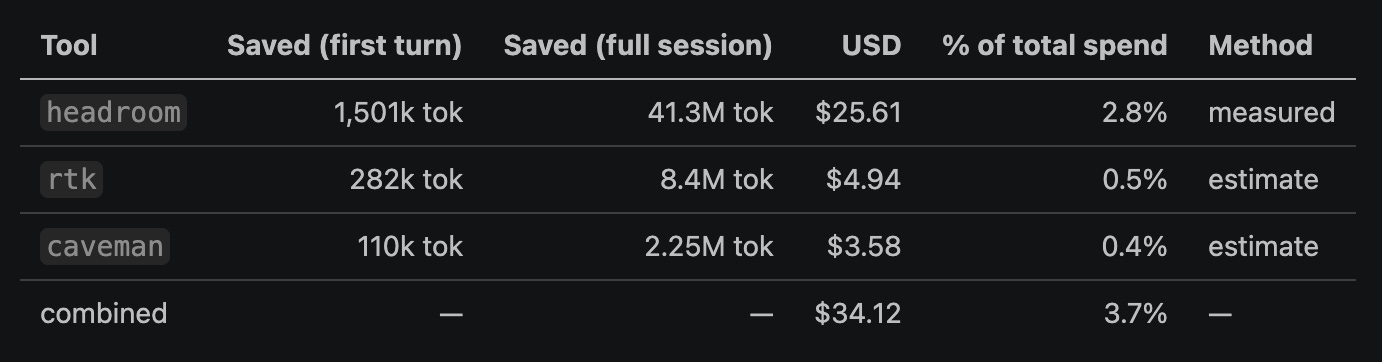
There is one thing to keep in mind when reading the two token columns. Every model turn re-sends the entire context at the cheaper cache_read rate, so a tool-result is paid for again on every later turn until the session ends. The first-turn column counts what a compressor removes the first time a payload appears, the full-session column counts that same payload on every turn it is re-sent afterward. Compressing once therefore saves tokens many times over. headroom‘s 1.5M first-turn tokens add up to 41.3M across the full sessions, about 27 times as much. The USD column prices the full-session savings.
There are two findings the microbenchmark cannot show. The first is the lifetime growth above, around 26x on average across the three tools, which comes from re-sending the same compressed payloads turn after turn. The second is that rtk reaches only 22% of tool-output tokens, because 78% flowed through native tools that bypass its shell hook, almost all of it the Read tool. There is one caveat on the lifetime figure. Claude Code compacts a session when its context fills and drops old tool-results, but only two compaction events showed up across all 500 sessions. The multiplier assumes payloads survive longer than they usually do, so it is an upper bound. Real compaction lowers the savings, which only strengthens the small-slice conclusion.
Routing a custom agent’s reads and searches through rtk grep or rtk cat recovers little of that 78% on this corpus. The bypassed stream is 78% file reads, and a file read has none of the near-identical line redundancy that lets rtk collapse a grep dump by 99 percent. rtk‘s file filters only dedup repeated lines and truncate, and truncation drops content the agent asked for. The next largest bypassed streams, WebSearch, WebFetch, and subagent results, have no rtk filter at all. Applying rtk‘s published file-read rule to the recorded Read sizes adds about $5 in a realistic case, doubling rtk‘s savings to roughly 1 percent of spend, and about $25 in an optimistic ceiling that assumes reads compress as well as grep dumps. The 78% is mostly content rtk cannot shrink without losing data.
Wide gap between fewer tokens and a lower bill
headroom advertises 60–95% fewer tokens (README.md:11), rtk 60–99% per recognized command, and caveman halves prose. The replay shows them saving 2.8%, 0.5%, and 0.4% of spend. None of the advertised numbers are exaggerated. Each measures a different thing on a different workload, and three layers separate a fewer-tokens claim from a lower bill.
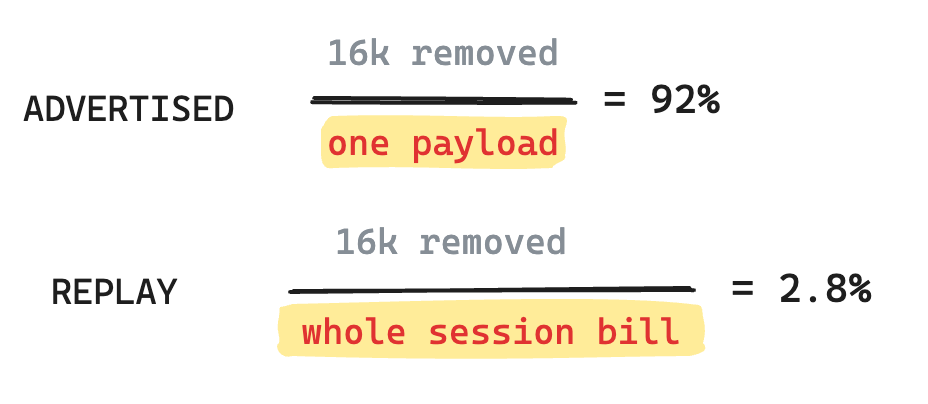
The first layer is the denominator. Compressing one synthetic code-search payload from headroom‘s README table 92% removes about 16k tokens (README.md:110). headroom divides those 16k by the size of that single 17,765-token payload, so the figure is 92%. The replay divides the same 16k by the whole session bill, which spans hundreds of turns and is dominated by cache and output costs far larger than any one payload, so the figure is 2.8%. The other two tools use the same narrow denominator. rtk divides its savings by the single shell command it recognized, and caveman divides by the prose in one answer. The replay divides all three by the whole session bill.
The second layer is the workload, the largest gap of the three. How much headroom compresses depends on the payload type. Its strongest strategies delete redundant rows, so they only pay off on structured, repetitive data like a JSON array or a search dump. Its benchmark table is built entirely from that type, generated synthetically rather than captured from real traffic. The “Code search (100 results) = 17,765 tokens” row comes from a generator that emits 100 Elasticsearch-style JSON records, exactly the redundant dump SmartCrusher compresses 80–95%. On my own workloads headroom activated on 45% of payloads, and the median reduction was 25%, not 60–95%, because most were plain text and source code with little duplication. The high-compression strategies fired on just 46 of 2,781 activations.
rtk and caveman miss their advertised workload the same way. rtk‘s 60–99% assumes a redundant dump like a grep result or directory listing, but 78% of tool-output tokens never reach its shell hook, and many that do are only a few lines long. caveman‘s 50% assumes the turn is mostly prose, but real answers mix in code blocks it excludes and short replies with little to shorten. Each figure is measured on the one payload type that compresses best, and that type is a small part of real traffic.
The third layer is pricing, which headroom‘s number omits. Tokens are not billed uniformly. At Opus 4.8 rates, fresh input costs $5 per million, a cache write $6.25, output $25, and a cache read $0.50. The sample’s $926 spend is mostly cache_create (42%) and output (29%), the two streams none of these tools change. headroom‘s and rtk‘s savings land mostly in cache_read, because both compress tool-result payloads that enter the context and are re-sent at the cache_read rate on every later turn. The first appearance is billed once as a cache write, but the many re-reads after it carry most of the cost, so most of what these two tools remove is cache_read, the cheapest token in the bill at one tenth the fresh input rate. caveman is the exception, since it shortens the model’s output as it writes and output is the most expensive token at $25 per million.
I would not say that the advertised number is exaggerated. The microbenchmark measures the best case on a single token stream. The replay measures what actually reaches your bill once every stream is blended together. A “fewer tokens” claim stops being a “lower bill” claim once prompt caching is involved, and how much these tools save depends on how much of your bill sits in the streams they touch. headroom and rtk cut tokens that are billed at the cheap cache_read rate, so they barely move a bill dominated by cache_create and output.
Cybersecurity risks of running each tool
Each tool sits where it can read your code, prompts, and command output. There are two separate questions here. What the honest code exposes today, and what a compromised version could do tomorrow.
Risk if the code is honest
The exposure differs by where each tool sits and whether anything leaves the machine. The tools below are ranked by how much trust they require, from lowest to highest.
rtk is local and narrow. It filters command stdout, runs real binaries with separate arguments so there is no shell-injection surface, and stores token metrics locally with no network calls outside opt-in telemetry. The real risk is correctness, not data theft. A filter that drops the one warning line that mattered leaves the agent with an incomplete view, and recovery depends on it re-running with --no-compact.
caveman is mostly local hooks with one boundary crossing. Base mode only injects prompts. The /caveman-compress workflow sends file contents to the Anthropic API to rewrite them, and defends that path well. It refuses sensitive paths (.env*, *.pem, *.key, anything under .ssh, .aws, or .kube) and caps file size. Its mode hooks write flag files with O_NOFOLLOW plus atomic temp-rename to block symlink-clobber attacks. The remaining risk is that compression is the model rewriting your context. A bad rewrite of CLAUDE.md silently corrupts every future session.
headroom holds the maximal trust position. As a proxy it sees full prompts, full responses, and the Authorization header with your API key. It passes the key through verbatim, strips its own internal headers before forwarding, and redacts keys from logs. But its CCR cache writes uncompressed content to local SQLite, briefly, so a snapshot of sensitive output lands on disk.
The shared risk across all three is not data leaving your machine, since they are local-first by default. It is silent lossy compression giving the agent a partial view. caveman trusts the model to self-compress, rtk trusts an allowlist with raw fallback, and headroom trusts specialist compressors but is the only one that can retrieve the dropped bytes.
Risk if a release is compromised
The ranking above assumes the code does what it says. All three are young projects, the kind that can be compromised in a future release the way recent supply chain attacks were. The 2024 XZ Utils backdoor came from a contributor who spent two years earning maintainer rights, then shipped a backdoor in the release tarball that was never in the public source. The 2025 Shai-Hulud worm and the 2026 axios compromise took the faster route, stealing a maintainer’s publish account and pushing a poisoned version that stayed live for hours. Either way, the code you read is not always the code you run.
So local-first is a property of today’s code, not a guarantee. A malicious version of any of these tools adds a network call in one line, and the data exposure ranked above is exactly what it would use.
headroom is the most exposed. A compromised proxy sees full prompts, full responses, and the Authorization header with your API key, so one bad release can steal the key, copy your private code, or edit responses to steer your agent.
rtk turns a compromised release into arbitrary command execution. It runs on the shell hook, so a bad version can swap commands, run extra ones, or send their output off the machine. You may not even install it yourself. headroom wrap claude downloads the rtk binary for you, so a poisoned rtk can reach you through headroom without you choosing the version.
caveman runs node hooks on session start and on every message. A malicious hook is code execution on every prompt you send. Base mode stays local, but the compress workflow already calls the API, and a bad version could widen what it sends or remove its sensitive-file filters.
Takeaway
On the content built for each tool, the savings are real. headroom cuts grep and diff payloads a median of 54 percent, rtk cuts recognized shell output 33 to 99 percent, and caveman halves prose. But replayed over a 614M-token corpus of my own Claude sessions ($926 of spend), the same tools saved 2.8 percent, 0.5 percent, and 0.4 percent, 3.7 percent combined. Every turn re-sends the context at the cheap cache_read rate, and the bill is 42 percent cache_create and 29 percent output, the streams none of these tools touch.
The 3.7 percent comes from my own Claude Code history, so it is not a universal number. How much these tools save depends on your workload. Heavy shell and grep use gives rtk more to do, and repetitive structured tool-results give headroom more.
The trade-off to weigh is a potential future security risk. All three are local-first today, but each reads your code, prompts, and command output, and a single compromised release could turn that access against you. A bad headroom sees full prompts, responses, and your API key. A bad rtk runs arbitrary commands through its shell hook, and a bad caveman runs node code on every message. Before adding these tools, you should decide whether a small saving is worth giving all three that access and trust.