
[Docling] LeetCode in Production: Union-Find and Spatial Indexing for LLM
Performance · How a classic interview algorithm solves the O(n²) overlap problem in document AI

You’ve likely solved Union-Find problems on LeetCode (e.g., Number of Islands, Accounts Merge) and wondered: when would I actually use this?
Here is a real-world use case. Docling, a document AI toolkit that has processed millions of PDFs fed to LLMs, uses Union-Find to clean up overlapping bounding boxes from ML layout models. Without it, you’d get duplicate paragraphs and fragmented tables.
Why ML Models Return Overlapping Boxes
ML layout models (like YOLO, DETR, LayoutLM) don’t “understand” documents; they predict probabilities. A model might predict: “91% chance of a table here.”
docling-project/docling:layout_model.py#L198-L210
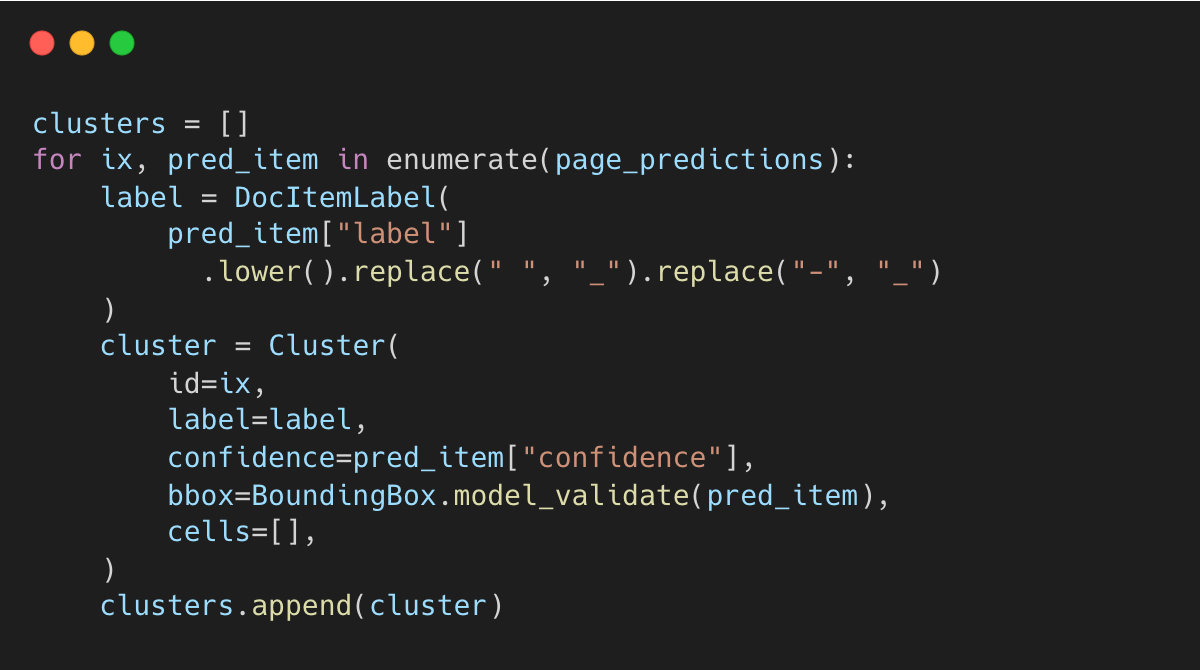
The model detects various document elements, like TEXT, TABLE, PICTURE, CODE, FOOTNOTE, and SECTION_HEADER.
These models are imperfect:
Duplicate detections: The same element appears multiple times with slightly offset boxes.
Fragmented tables: Large tables are split into separate regions.
Conflicting predictions: A “paragraph” detection bleeds into a “table” detection.
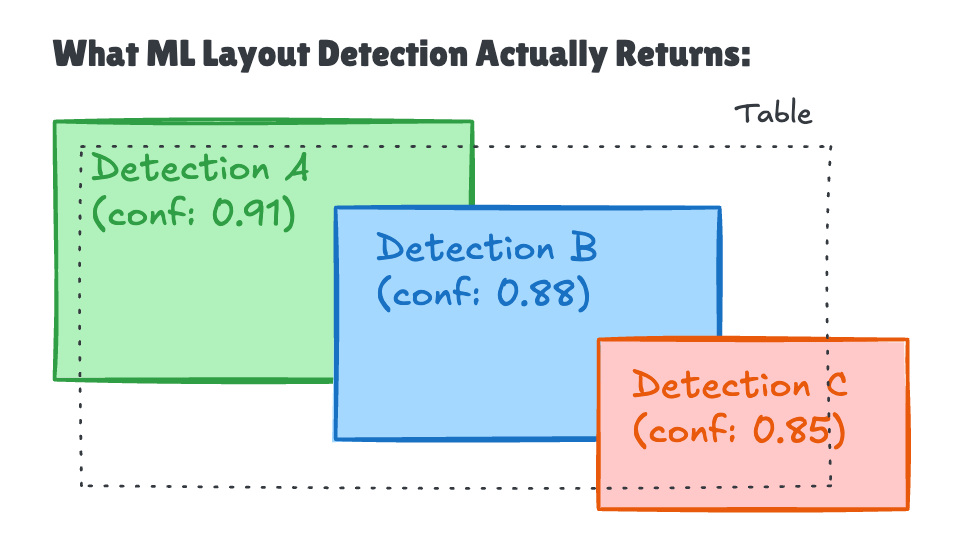
Box A overlaps B, and B overlaps C, but A doesn’t overlap C. All three detect the same table. How do we merge them?
The Problem: Transitive Overlap
Overlaps are transitive: if A overlaps B, and B overlaps C, all three belong to the same group and should be merged. Without cleanup, this results in duplicate paragraphs or fragmented content.
A naive approach is O(n²). Union-Find solves this elegantly by tracking connected components.
The Union-Find Implementation
Docling implements a minimal Union-Find class to avoid dependencies like scipy or networkx.
docling-project/docling:layout_postprocessor.py#L16-L46
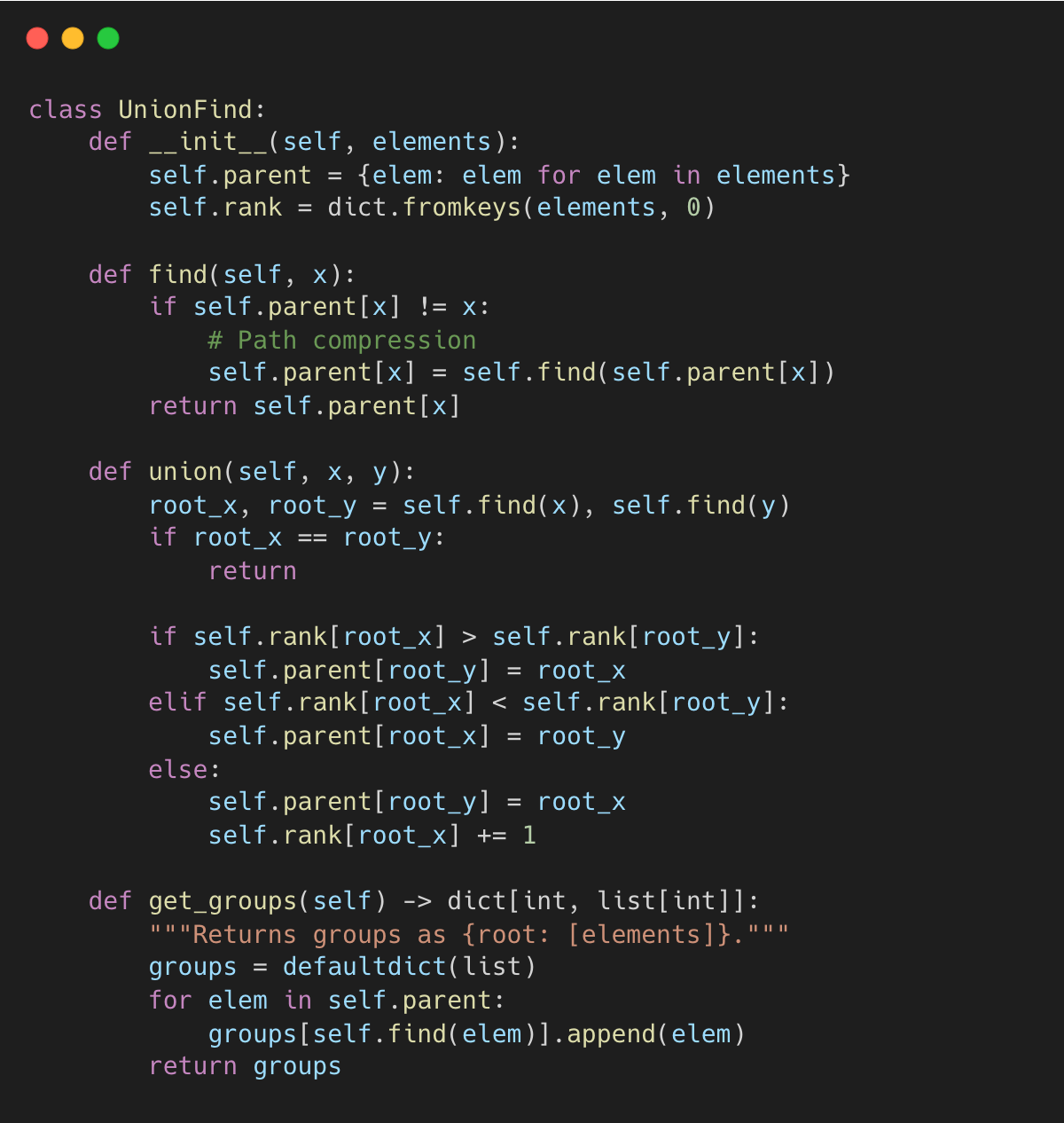
It includes two standard optimizations for near O(1) amortized performance:
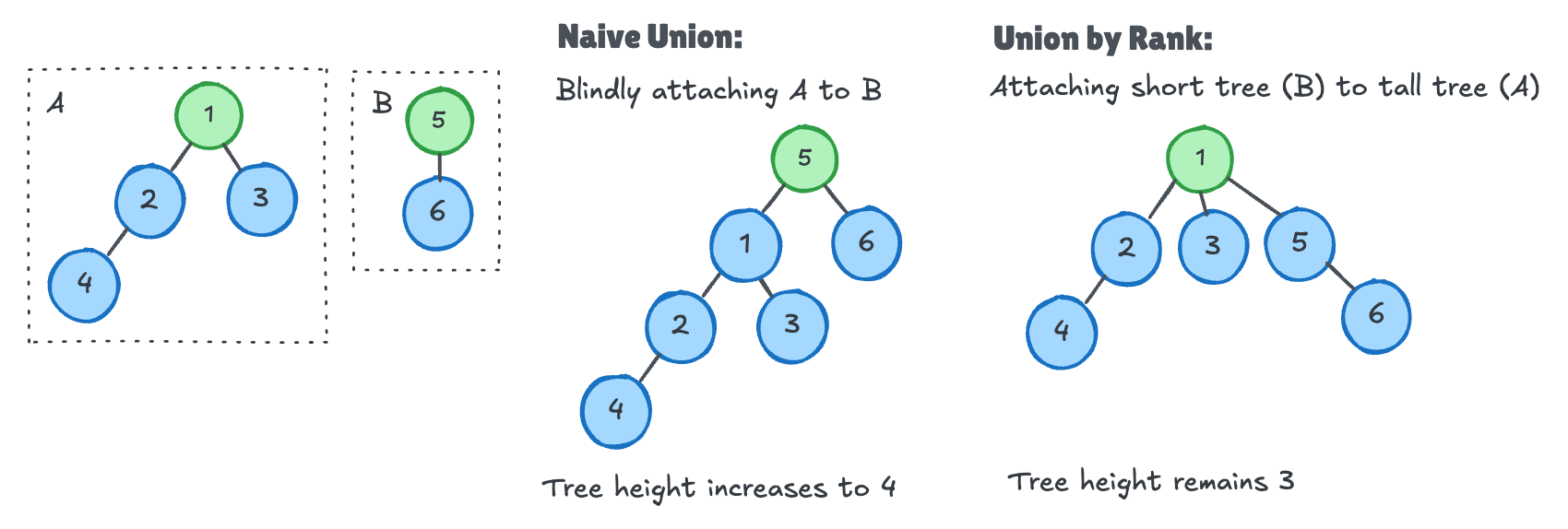
1. Path Compression: Flattens the tree structure during find().
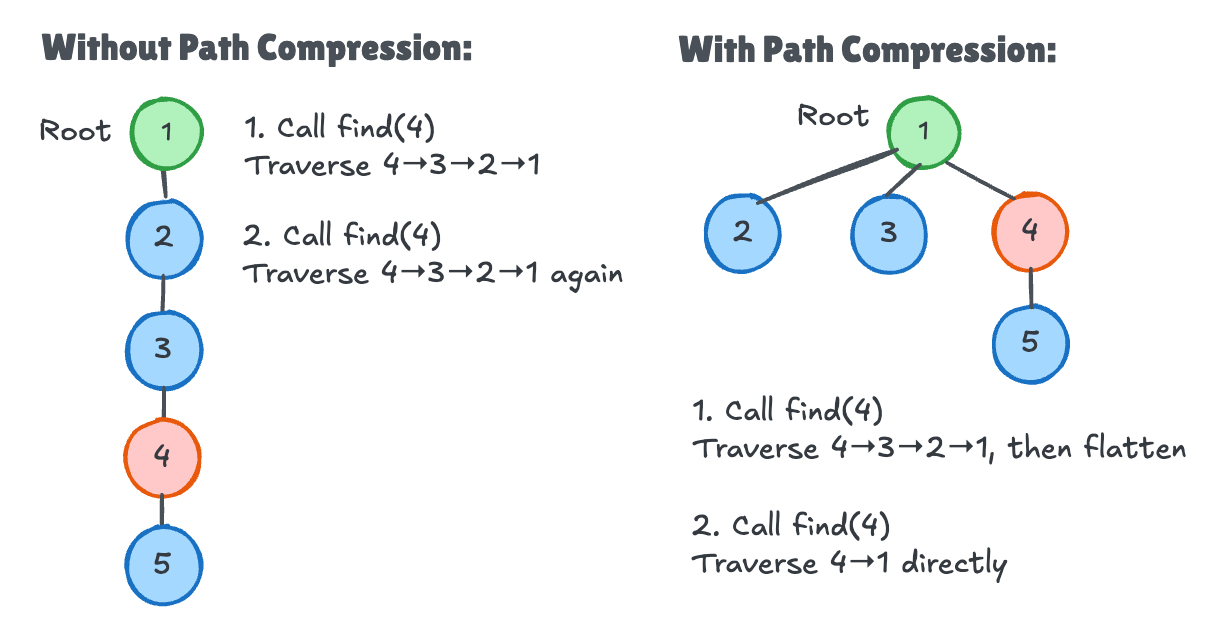
After one find call, all nodes on the path point directly to the root. Future lookups for these nodes are O(1).
2. Union by Rank: Attaches shorter trees under taller ones to minimize depth.
Finding Overlapping Candidates Efficiently
Union-Find groups boxes, but we first need to identify which boxes overlap. Pairwise checks are too slow for dense pages.
Docling uses spatial indexes to query nearby objects in O(log n):
1. R-tree: The classic spatial index for 2D rectangles.
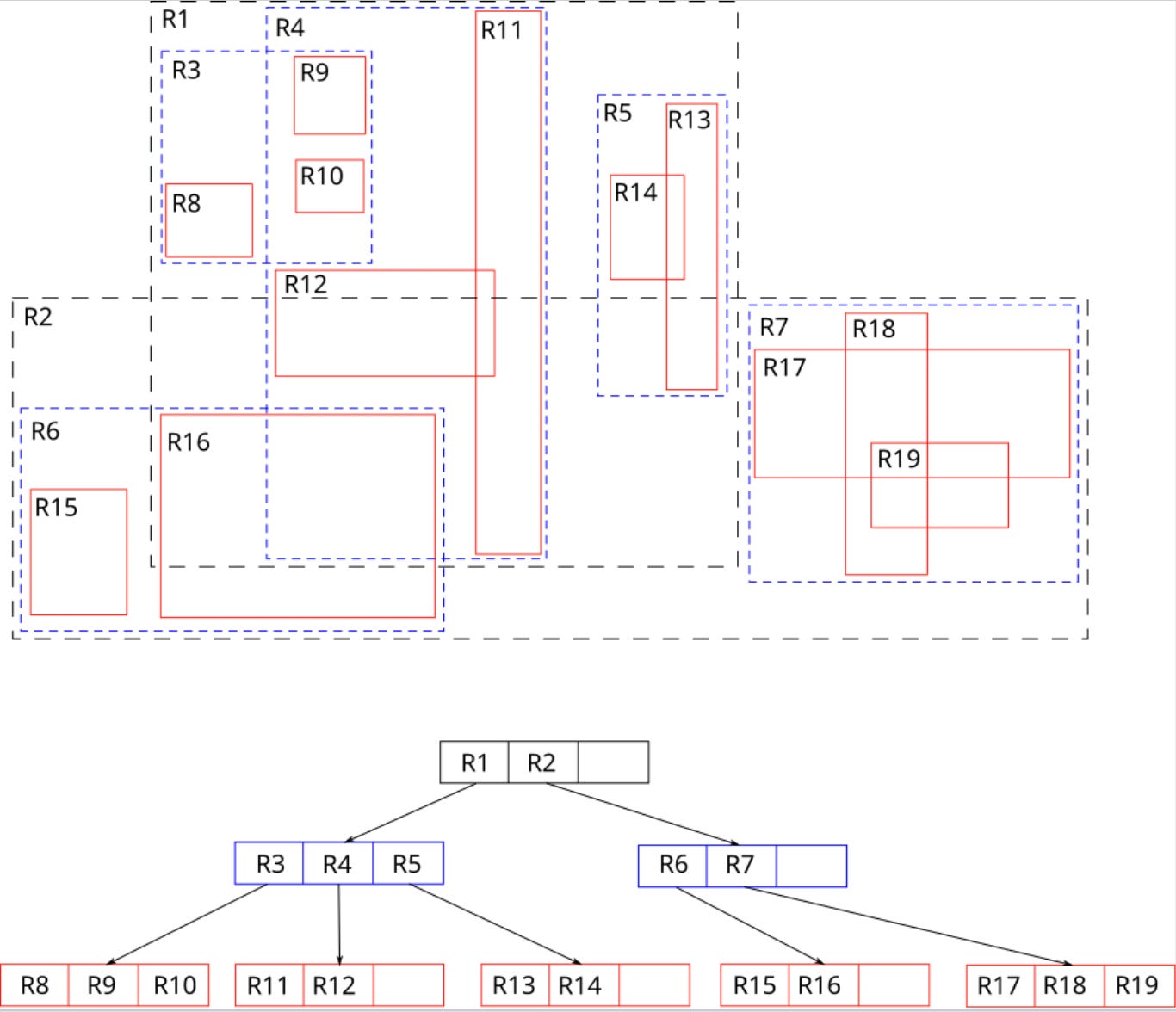
In the image above (source: Wikipedia), to find what overlaps R18, only R7 needs to be searched.
{kind=link}
2. Interval Trees: 1D indexes (like LeetCode’s Merge Intervals) for X and Y coordinates.
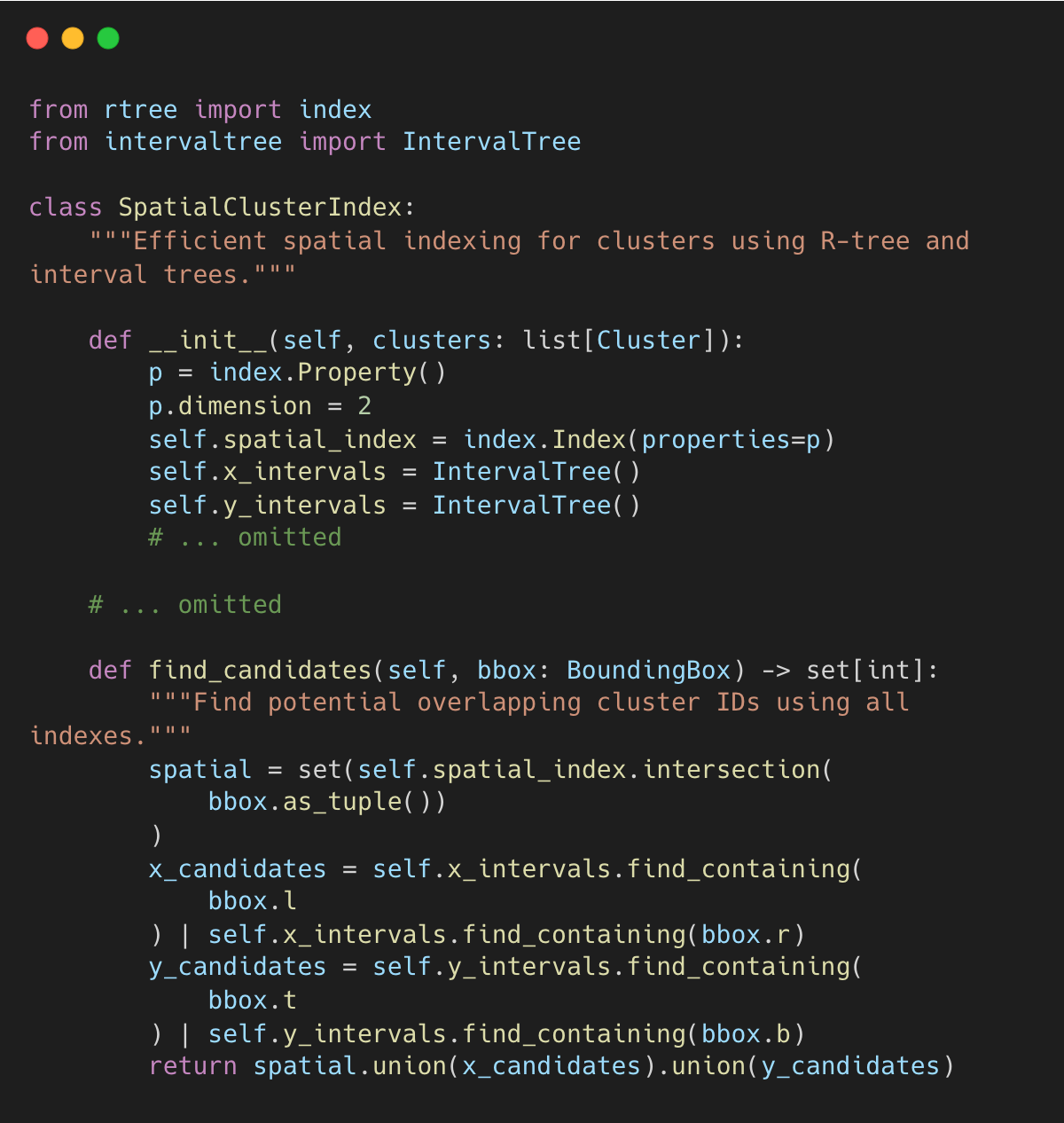
Triple-Index Strategy
Docling combines R-tree with Interval Trees for increased reliability.
docling-project/docling:layout_postprocessor.py#L49-L83
Putting It All Together
The complete flow from raw bounding boxes to deduplicated clusters:
Build Spatial Index: Insert all clusters (bounding boxes from the ML model) into R-tree and Interval trees.
Find Overlaps & Union: Query the index for candidates. If overlap > threshold,
union(A, B).Extract Groups:
get_groups()returns sets of connected clusters (e.g.,{A, B, C}).Select Best: From each group, keep one cluster (highest confidence) and absorb the text cells from the others.
docling-project/docling:layout_postprocessor.py#L487-L542
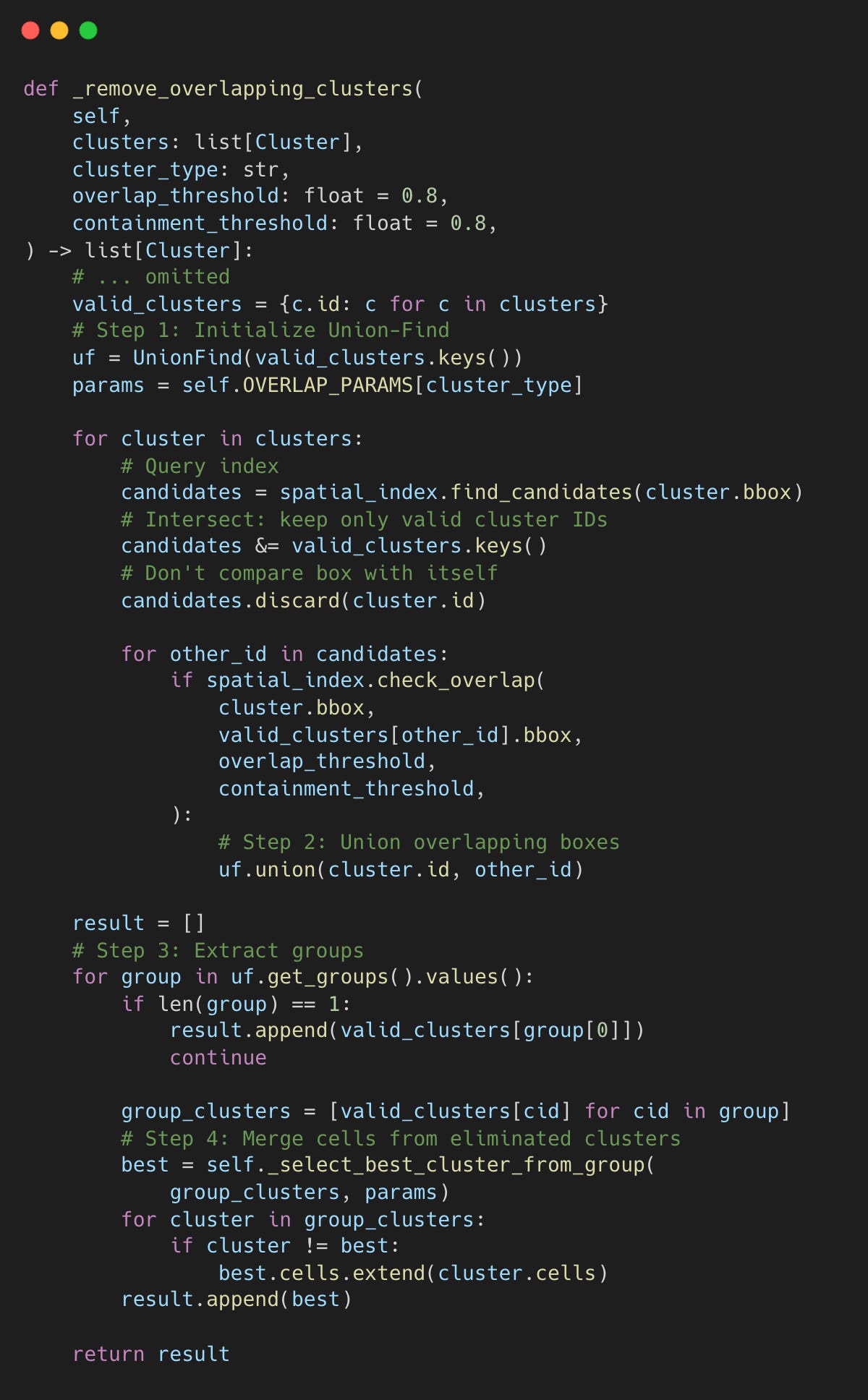
Spatial indexing enables efficient candidate discovery, while Union-Find handles grouping in a single pass.
Impact
Efficiency: Replaces O(n²) pairwise checks with near-linear spatial queries, enabling scalable processing of millions of documents.
Quality: Eliminates duplicate text and fractured tables from detection errors, ensuring clean data for RAG and downstream LLM reasoning.
Major Contributions
Please let me know if I missed any other major contributors to this feature!