
[llama.cpp] Accelerate Top-K Sampling by 2.9x with Bucket Sort
Performance · Code walkthrough of how filtering logits with a histogram avoids expensive sorting operations

Every time a language model generates a token, it scores every token in its vocabulary. Llama 3 has a vocabulary size of 128,256 tokens. For top-k sampling with k=128, you need the 128 highest scores out of 128,256 candidates in every generation step.
The standard approach uses std::partial_sort at O(n log k), but llama.cpp uses a method that makes top-k sampling 2.9x faster at k=8000. The secret is skipping the sorting you don’t need.
Build a Histogram (Pass 1)
Bucket sort exploits the limited range of token logits. In Llama models, logits cluster near zero, mostly between -10 and +10. A histogram over this range identifies which buckets contain the top-k candidates without comparing individual values.
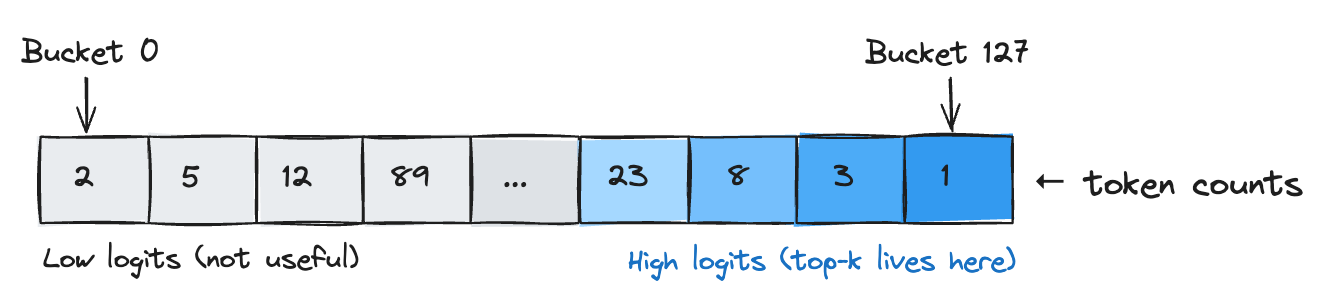
Below is the code for building a histrogram.
ggml-org/llama.cpp:llama-sampling.cpp#L133-L165
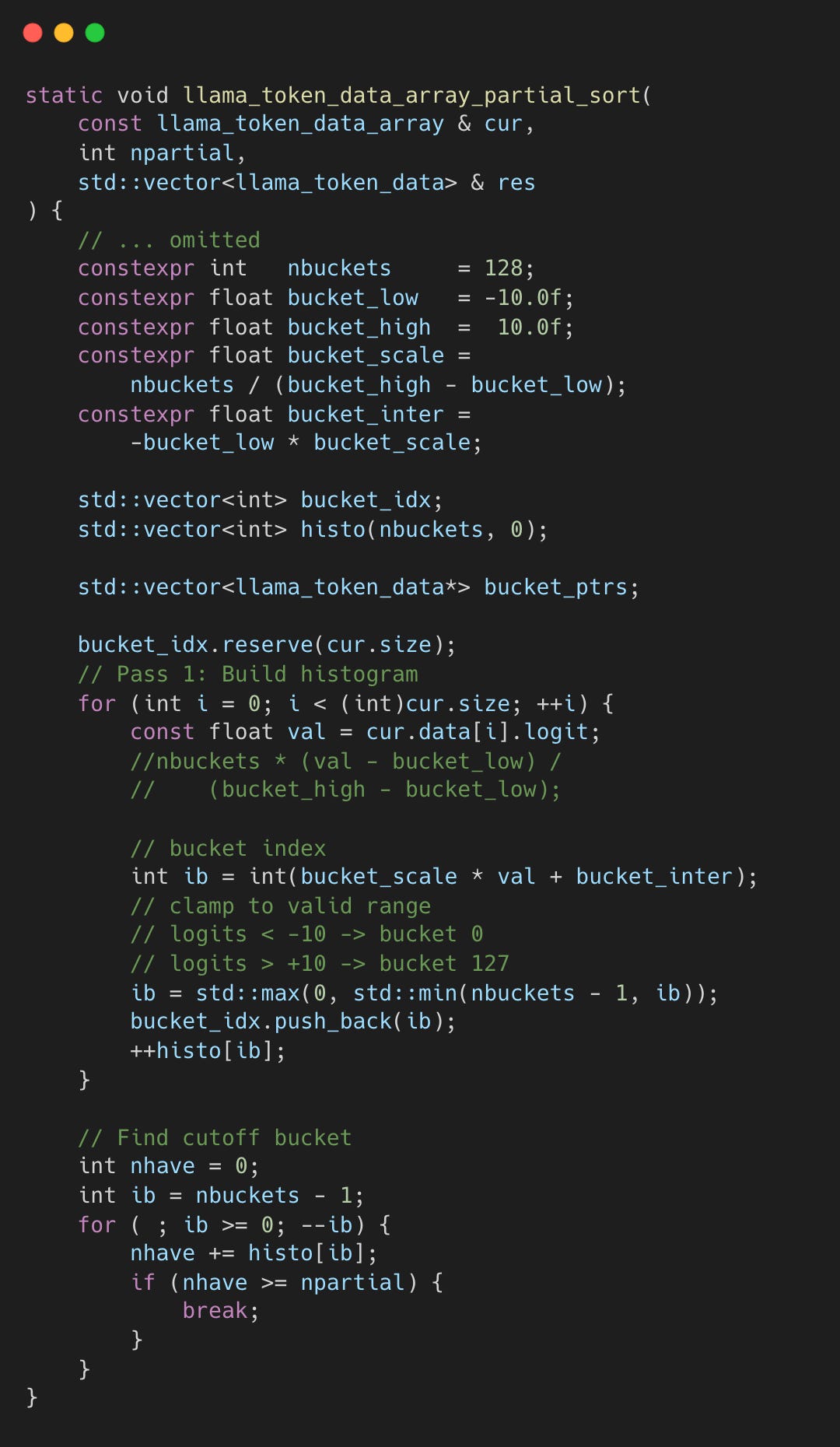
Pass 1 scans all tokens once, assigning each to one of 128 buckets based on its logit value - just a few arithmetic operations per token.
The code then iterates from the highest bucket downward, accumulating token counts. If bucket 127 has 5 tokens and bucket 126 has 12, the running total becomes 5, then 17, and so on. The bucket where this sum first reaches k becomes the cutoff (ib).
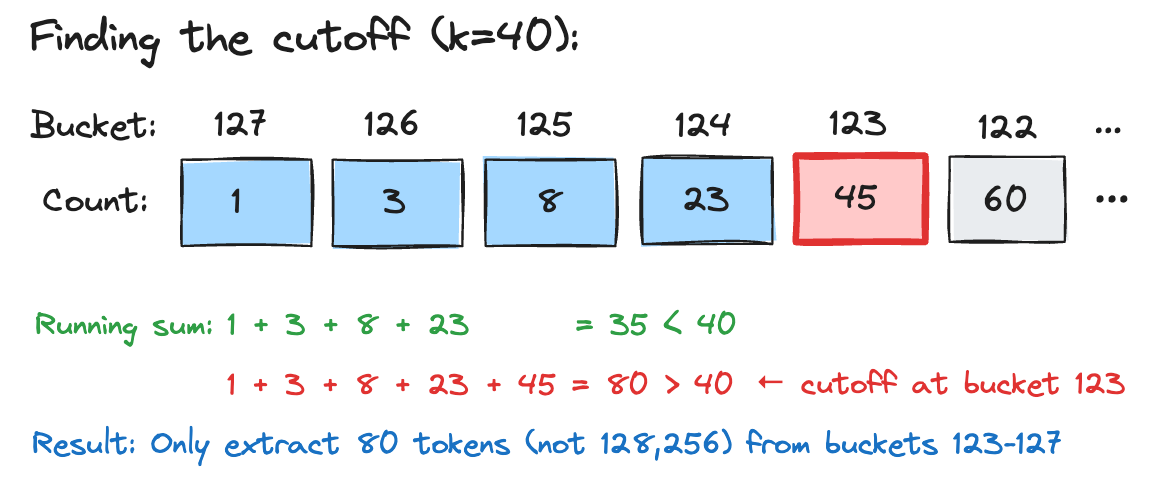
Scatter (Pass 2)
With the cutoff known, the second pass scatters qualifying tokens into a pre-partitioned result array. Each bucket gets its own write region sized by its histogram count, so tokens land in the right place without comparison.
ggml-org/llama.cpp:llama-sampling.cpp#L166-L178
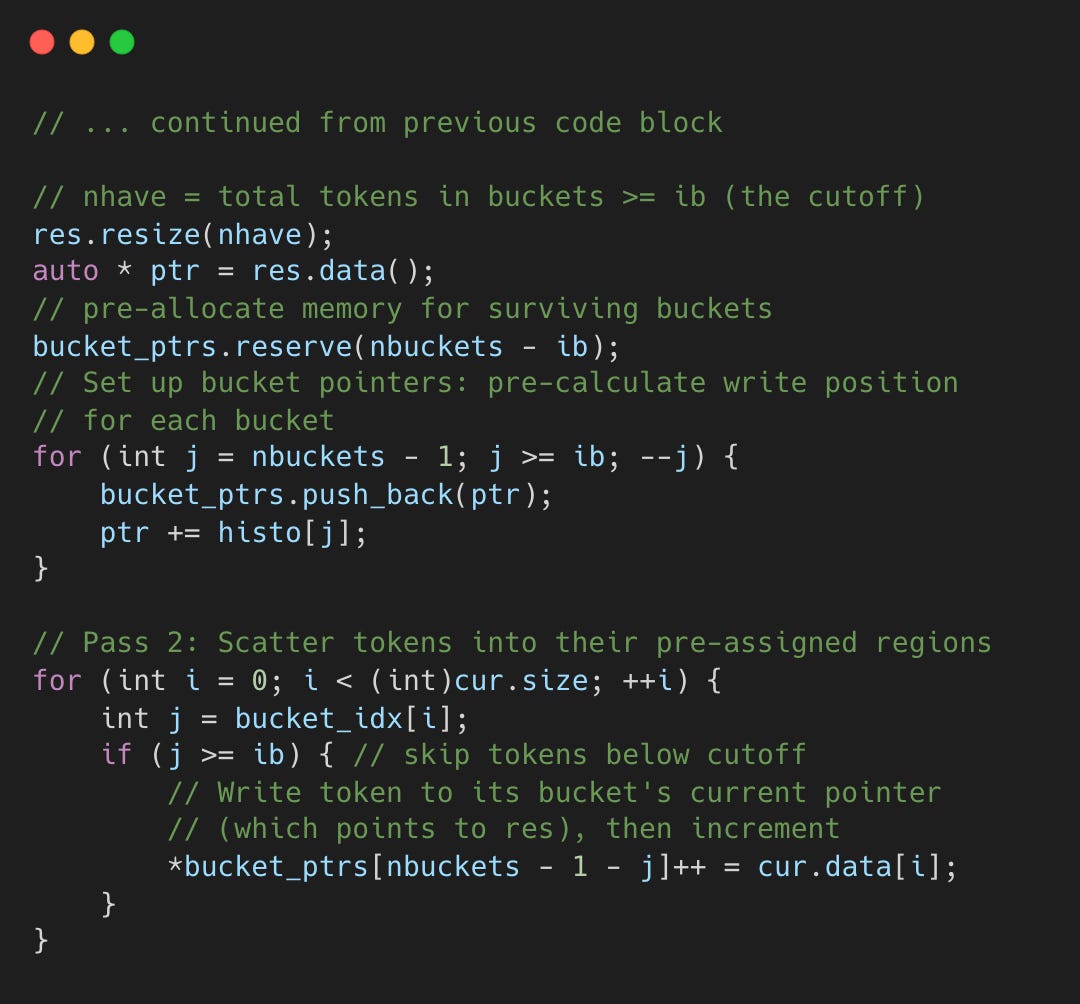
bucket_ptrs stores pointers into res, each marking where to write the next token for that bucket. Here’s an example of how scatter works.
Let’s say Pass 1 found: bucket 127 has 2 tokens, bucket 126 has 3 tokens, and we need these 5 survivors.
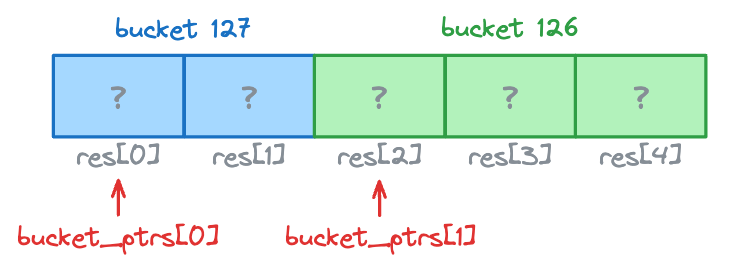
Setup: Partition res using histo counts.
res (output array, 5 slots):
Scatter: Write tokens through pointers
Process Token 1 (bucket 127): write to bucket_ptrs[0], then advance it
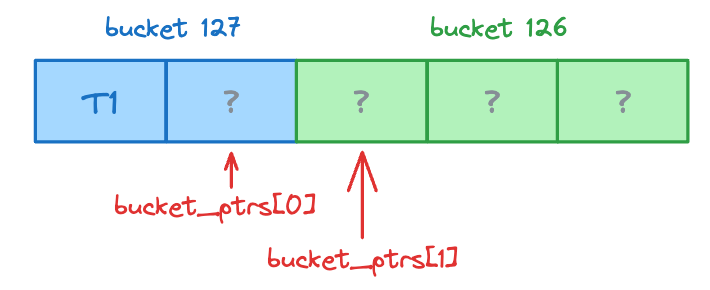
Process Token 5 (bucket 126): write to bucket_ptrs[1], then advance it
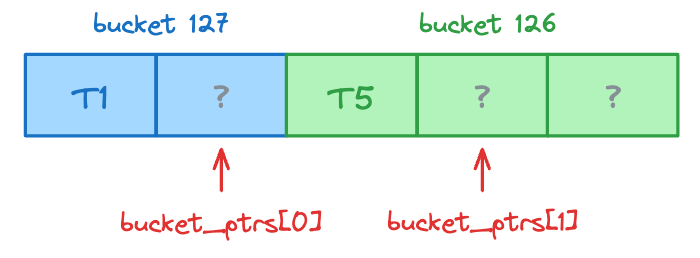
Process Token 3 (bucket 127): write to bucket_ptrs[0], then advance it
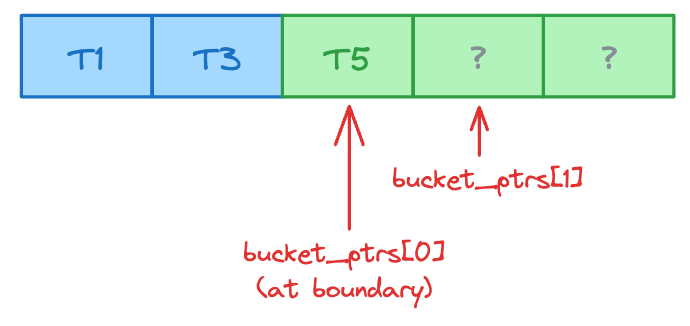
Once all tokens are scattered, res contains tokens grouped by bucket (unsorted within each bucket).
Sort
With tokens grouped by bucket, the final step sorts each bucket individually, resulting in comparisons of fewer tokens.
ggml-org/llama.cpp:llama-sampling.cpp#L180-L188

Buckets above the cutoff are fully sorted with std::sort. The cutoff bucket uses std::partial_sort since only some of its tokens are needed to reach k.
Threshold Decision for Bucket Sort
The algorithm decides the strategy (full partial sort vs. bucket sort) at k=128.
ggml-org/llama.cpp:llama-sampling.cpp#L191-L207
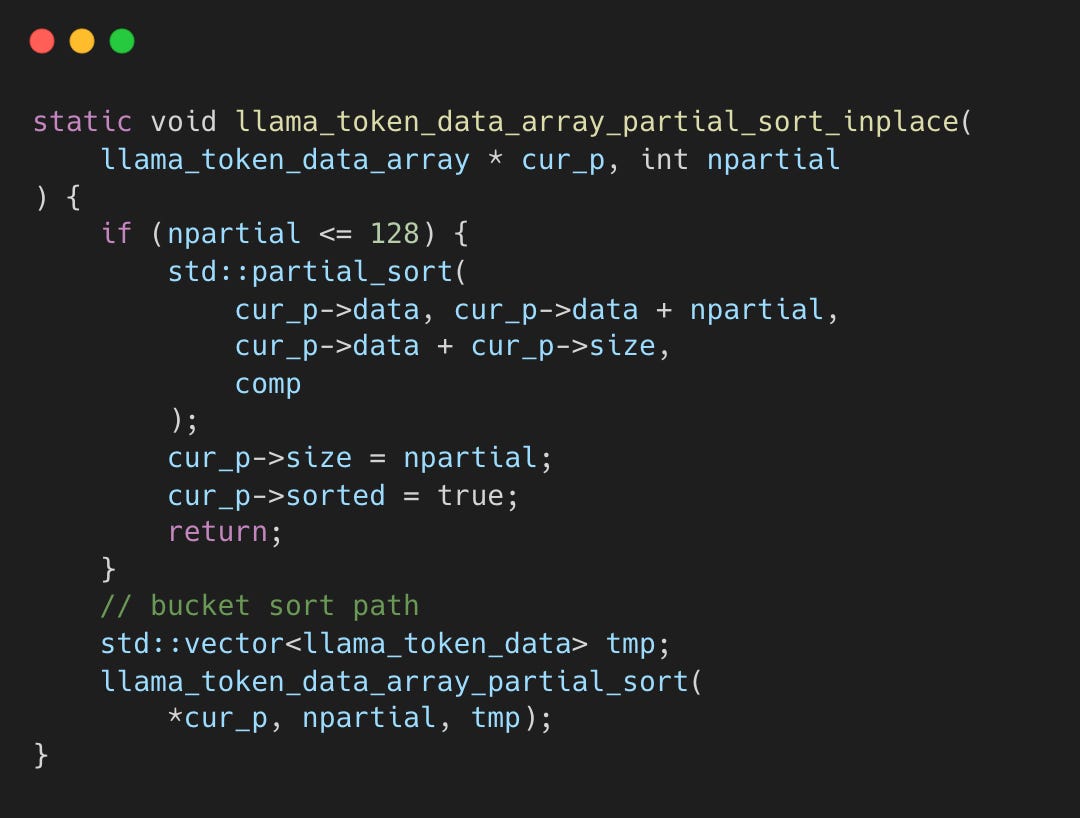
Bucket sort has fixed overhead regardless of k - two full passes over all 128K tokens. For small k, std::partial_sort at O(n log k) is already fast since log(k) is small, so the two-pass cost doesn’t pay off. For large k like 8000, the larger log(k) slows down std::partial_sort, so the sorting reduction from bucket filtering matters more, resulting in up to 2.9x performance. The crossover at k=128 is approximately where bucket sort’s fixed cost starts paying off.
Major Contributions
Please let me know if I missed any other major contributors!