
[x-algorithm] How X Decides What 550 Million Users See
Deep Dive · A code walkthrough of the feed algorithm X open-sourced on January 20, 2026

Architecture: Component-based Pipeline
The CandidatePipeline framework is the modular foundation, defining how recommendation stages interact.
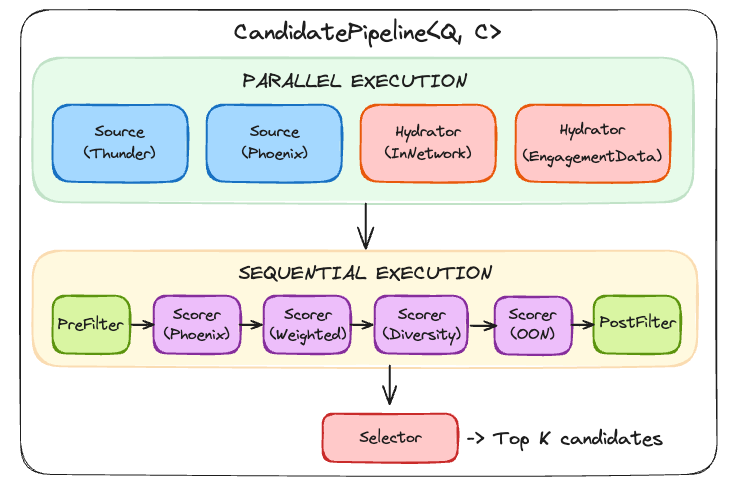
Key component types are
Sources fetch candidate posts. Thunder retrieves posts from accounts you follow (in-network). Phoenix serves as a general discovery engine, using ML similarity matching to find relevant posts across the entire platform (both out-of-network and in-network).
Hydrators enrich candidates with additional data, like whether a post is in-network, engagement statistics, author metadata.
Scorers and Filters evaluate and prune the enriched candidate pool.
Pipeline Execution Model
The CandidatePipeline trait defines the pipeline interface. Concrete implementations like `PhoenixCandidatePipeline` wire together the specific components.
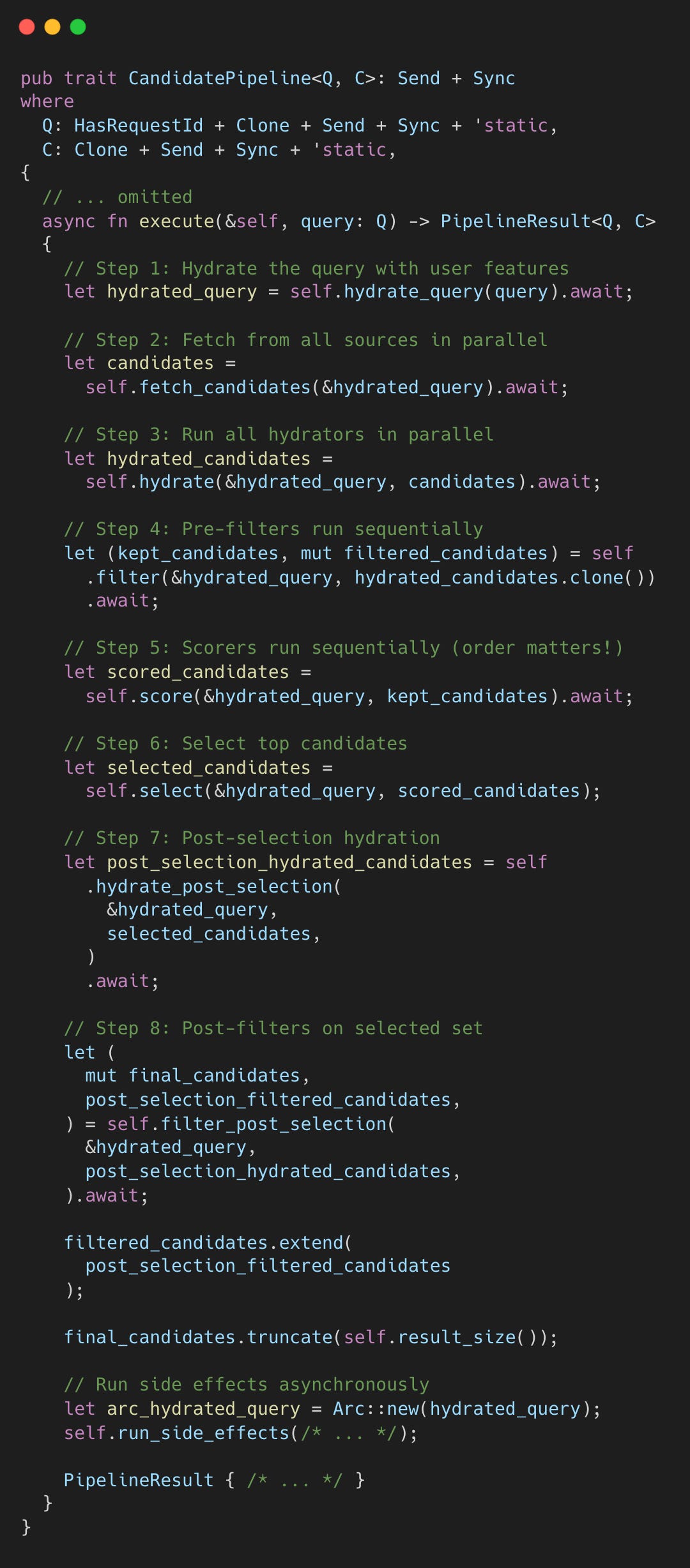
Every timeline request triggers the full pipeline. When you open “For You,” the server executes the entire pipeline.
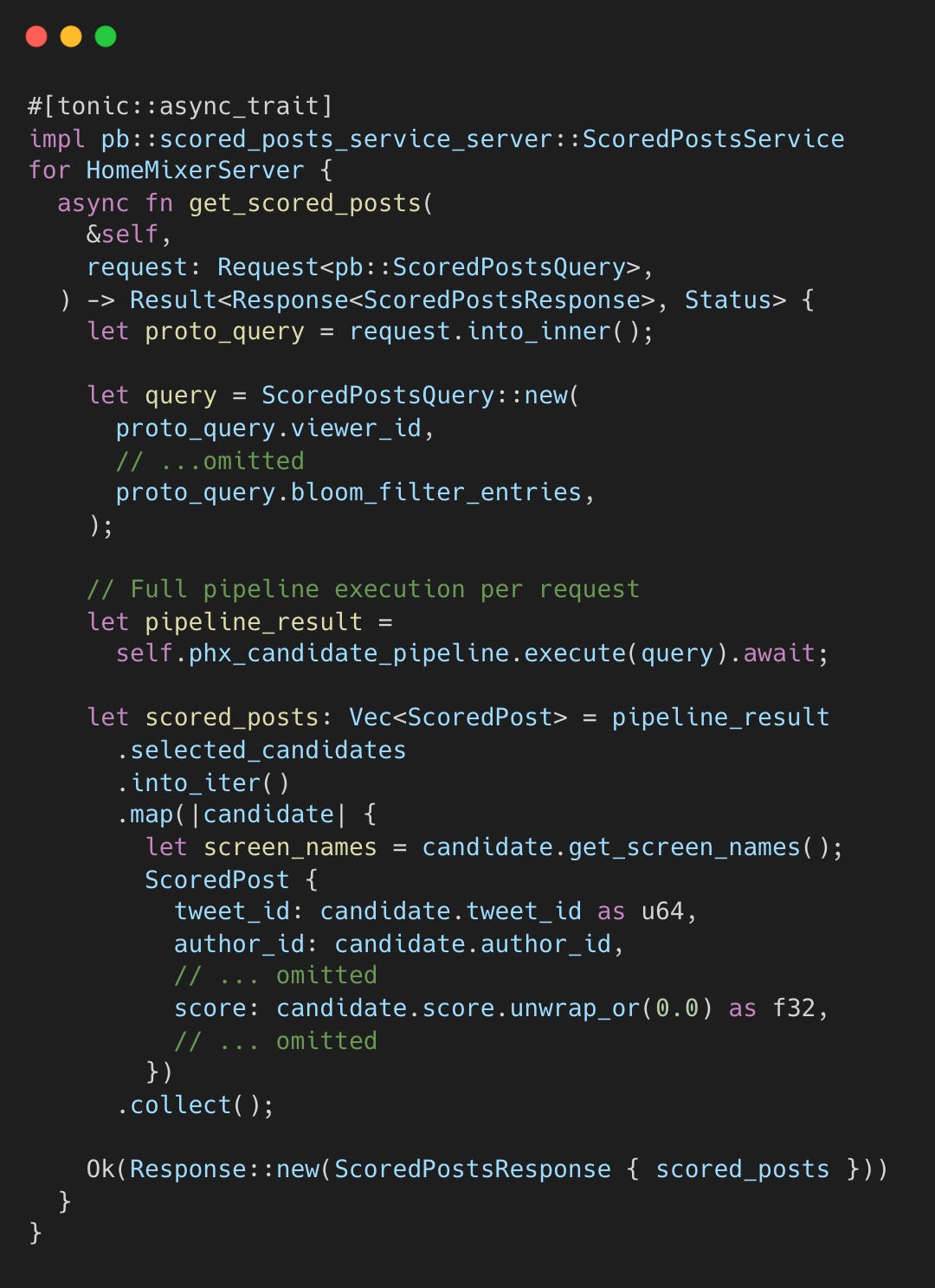
The Phoenix Scorer uses a Grok-based transformer to predict engagement. It generates a unique request ID and timestamp for each call:
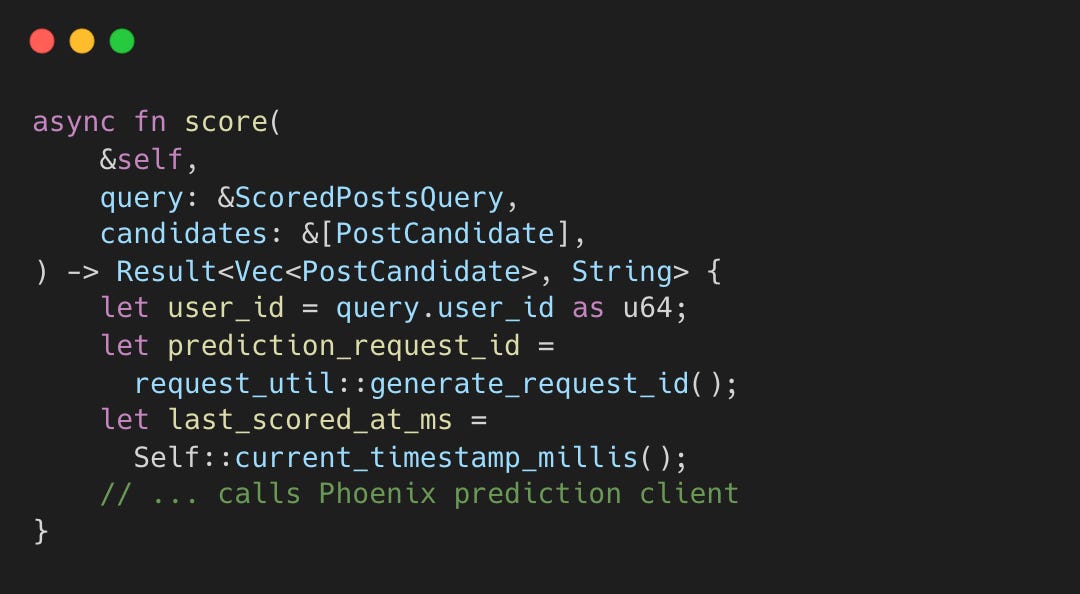
This means a post’s score can change between requests as engagement accumulates. For example, if User A sees your post at hour 1 (100 likes), and User B sees it at hour 3 (500 likes), Phoenix receives different engagement features and may produce different predictions.
Stage 1: Finding Candidates
The primary goal of retrieval is to funnel the massive corpus of millions of posts down to a manageable set of thousands of candidates for ranking.
In-network posts come from your follows. Out-of-network (OON) posts are discoveries based on your interests. In-network content keeps its full score, but OON content is penalized during ranking.
Two sources feed the pipeline: Thunder and Phoenix.
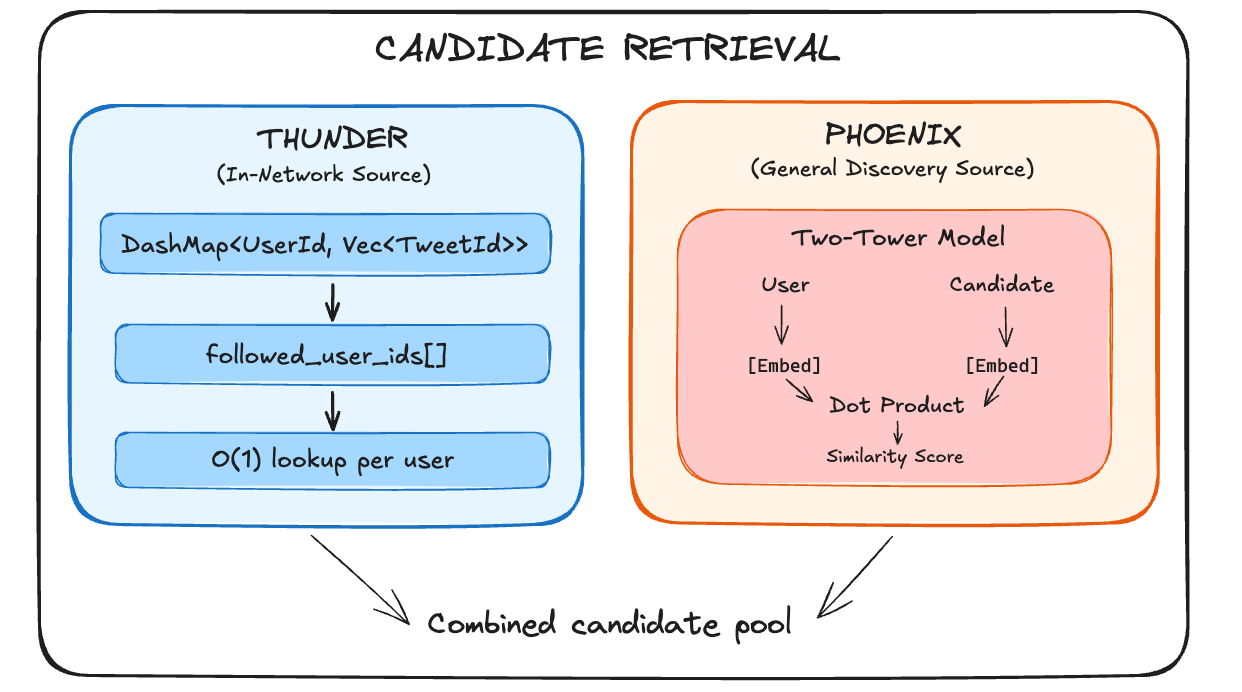
Thunder: In-Network Content
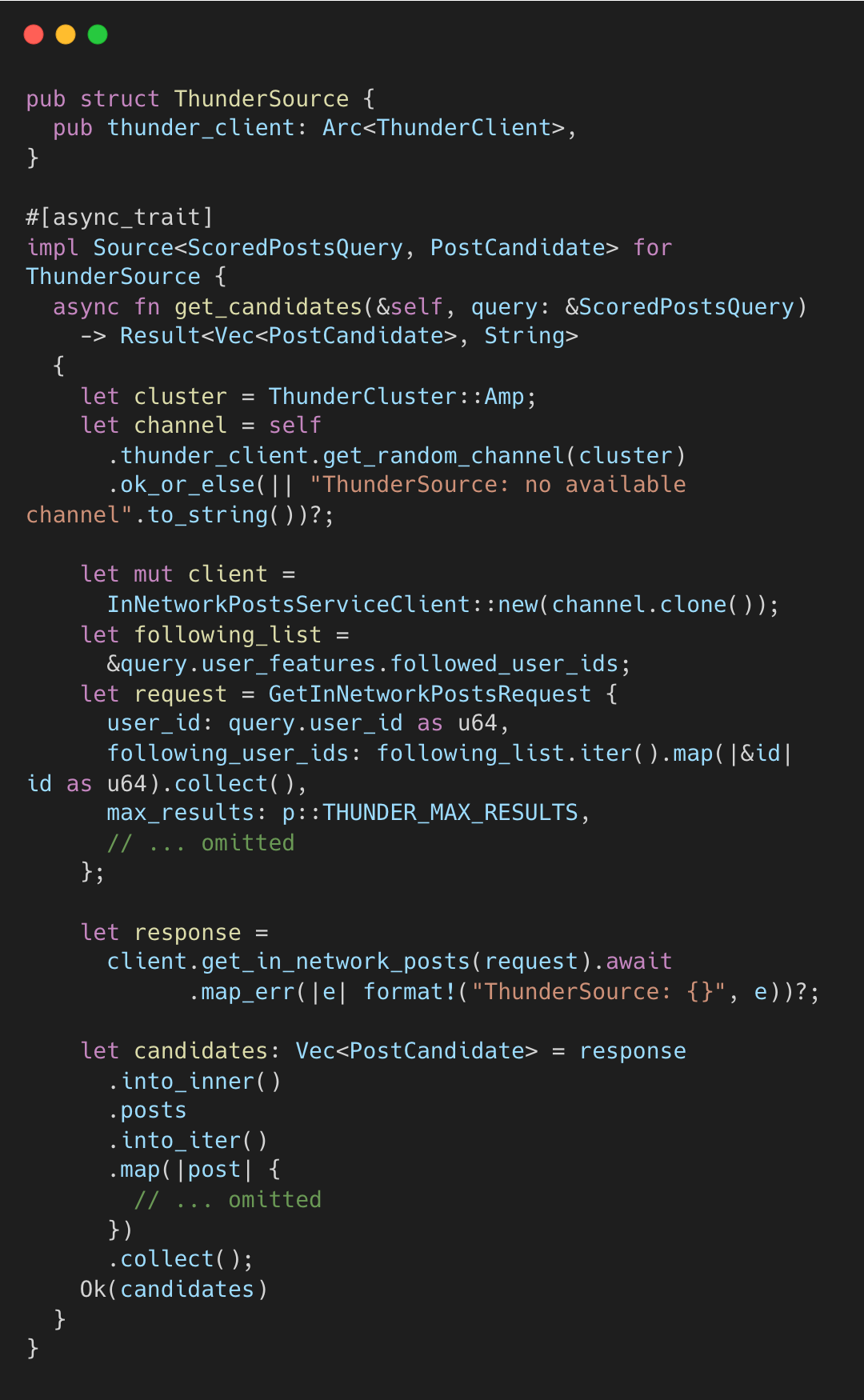
Thunder is a separate service maintaining an in-memory DashMap (concurrent HashMap) of the last 48 hours of tweets, indexed by author. home-mixer queries Thunder via gRPC:
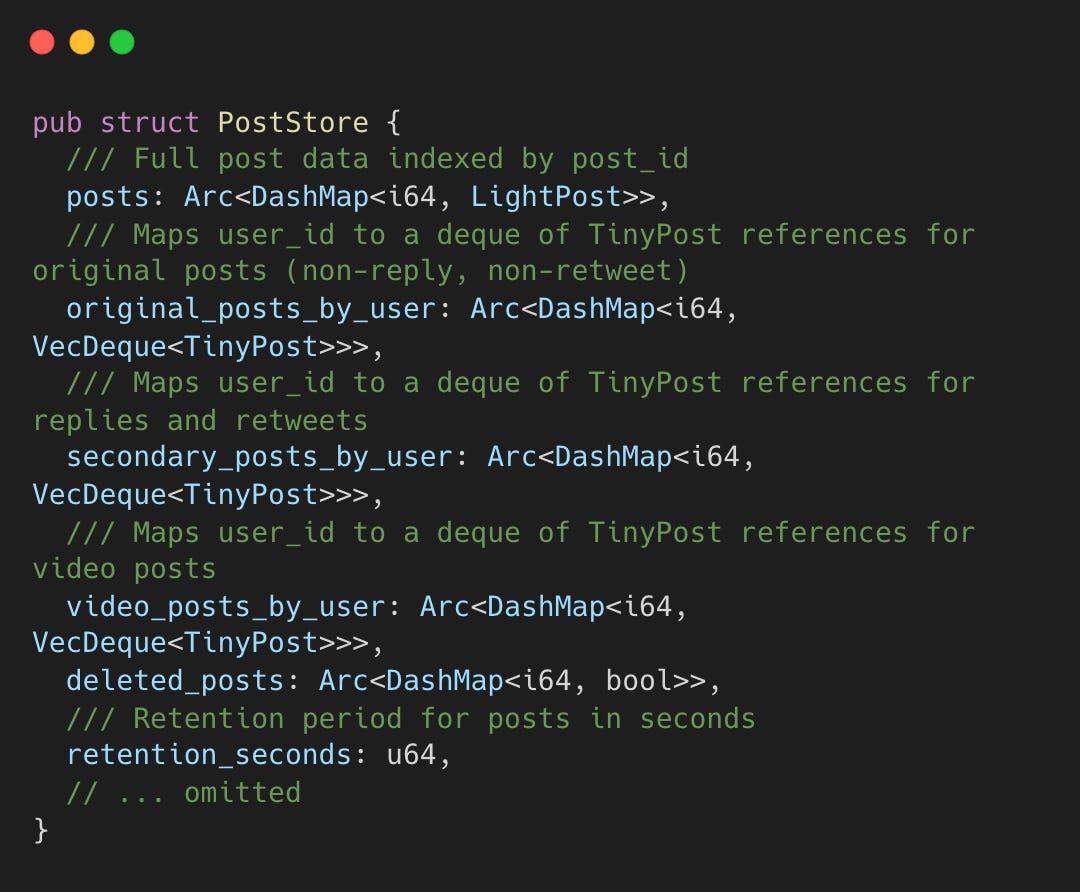
Thunder’s PostStore maintains indices for original posts, replies/retweets, and video content, enabling O(1) lookups.
Phoenix: Discovery
Phoenix uses a two-tower neural network for retrieval.
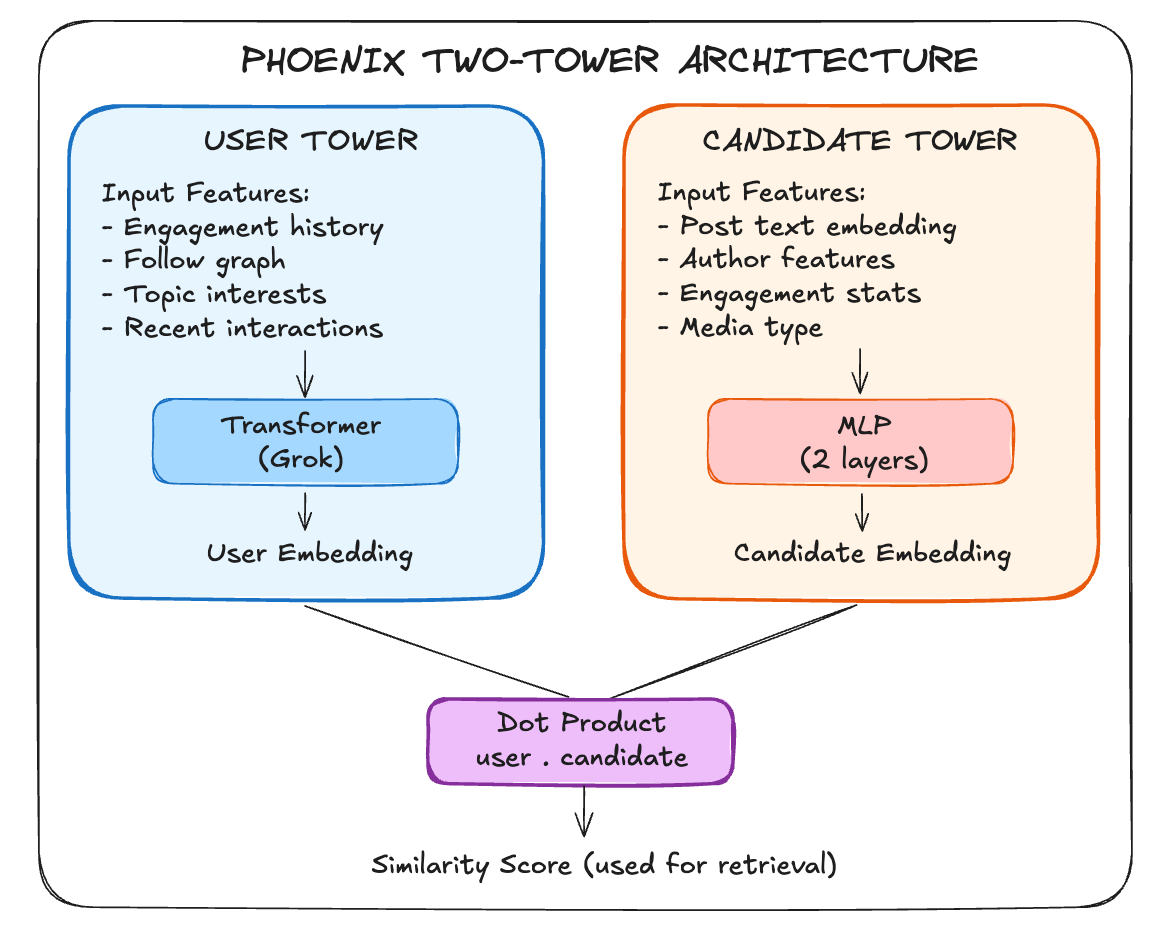
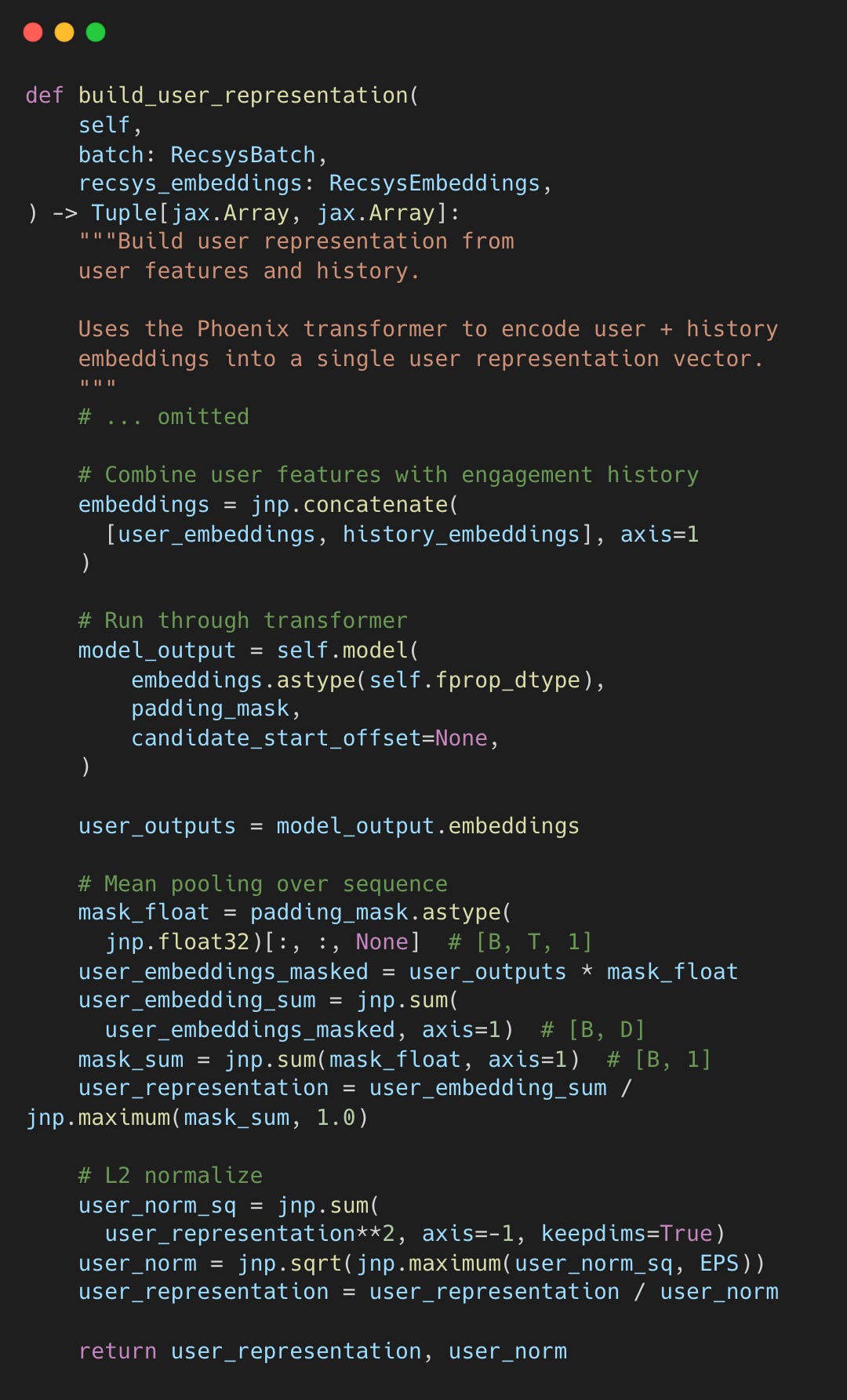
User Tower: Transformer + Mean Pooling
The user tower feeds user features and engagement history through the Grok transformer, then mean-pools the output.
recsys_retrieval_model.py#L206-L276
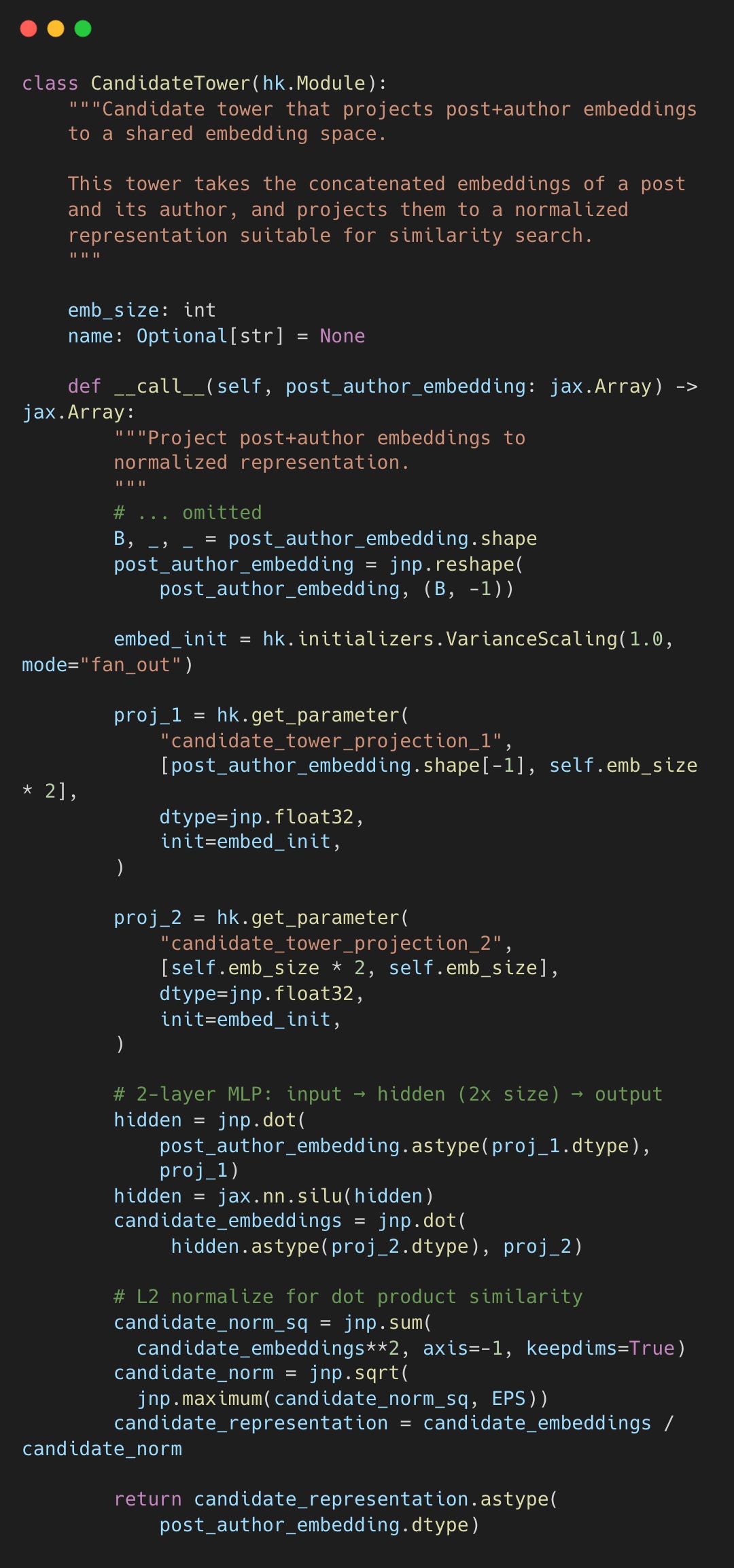
Candidate Tower: A 2-Layer MLP
The candidate tower is simple: a 2-layer MLP with SiLU activation projecting post+author embeddings into the shared space.
recsys_retrieval_model.py#L47-L99
Retrieval: Dot Product Over Corpus
With L2-normalized embeddings, retrieval is a matrix multiplication:
recsys_retrieval_model.py#L346-L372
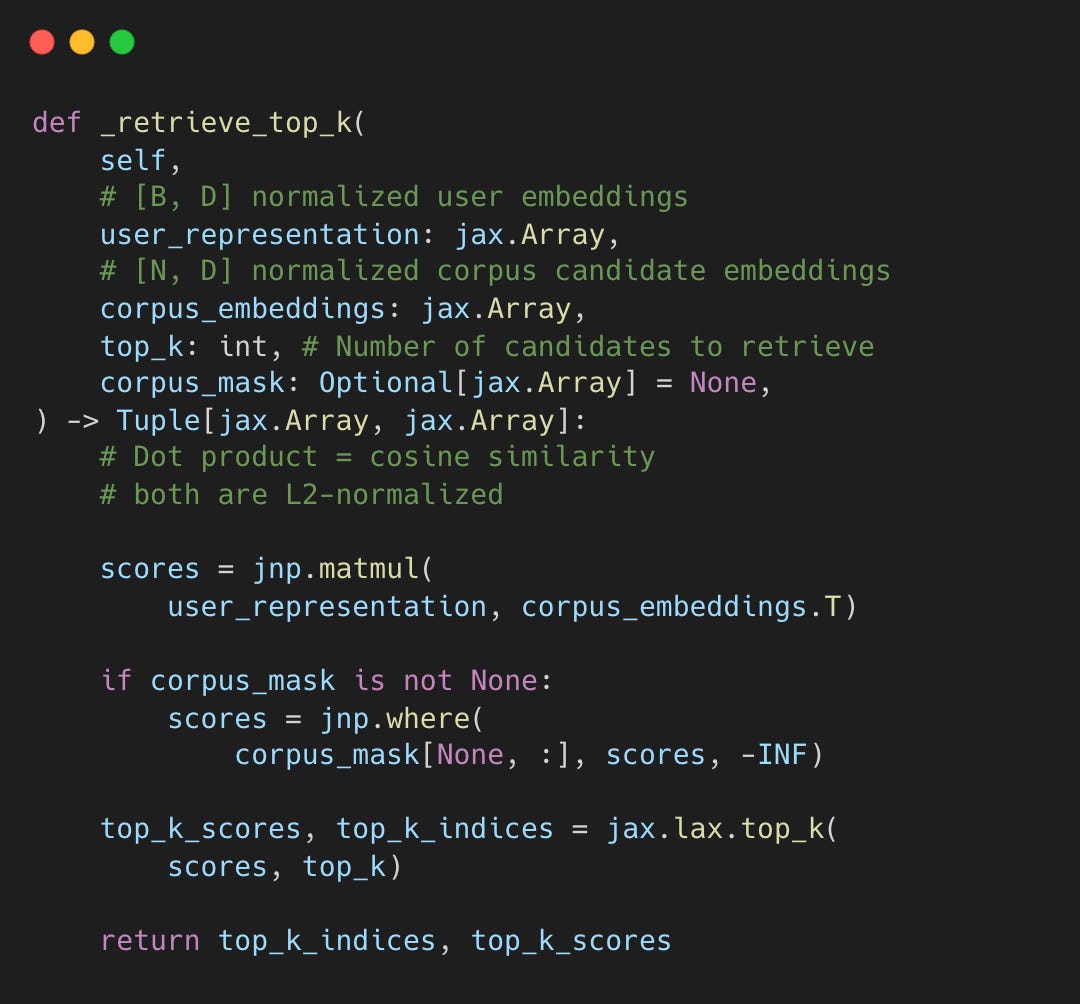
At request time, Phoenix generates a single user embedding to query millions of precomputed candidates. Top-k selection uses dot product similarity, likely optimized via Approximate Nearest Neighbor (ANN) to avoid the latency of a brute-force search.
Thunder and Phoenix return a pool of candidate posts, each as a PostCandidate struct. Classification happens next.
Stage 2: Classifying In-Network vs. Out-of-Network
Before scoring, the InNetworkCandidateHydrator determines if a post originates from a followed account.
in_network_candidate_hydrator.rs#L10-L39
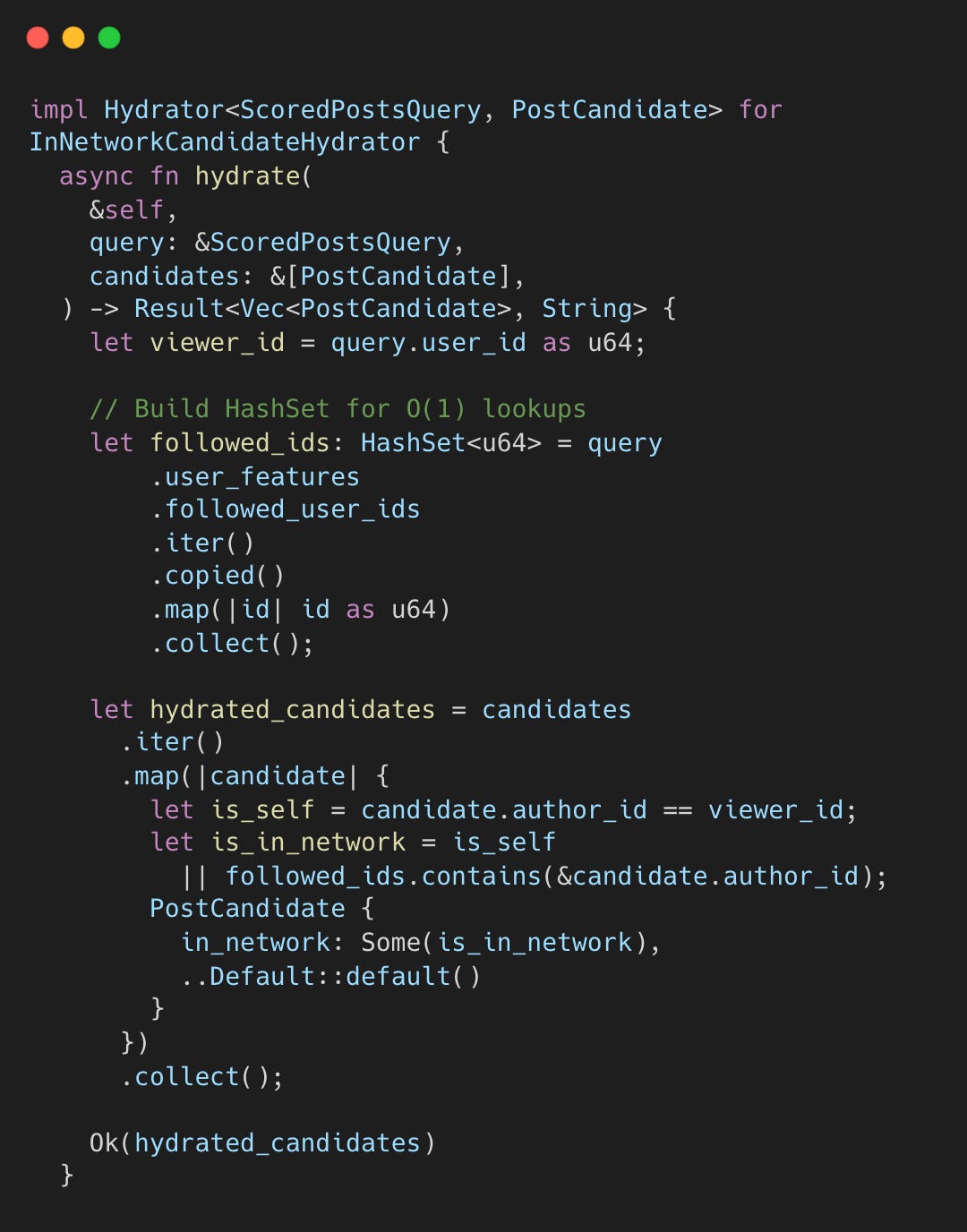
It converts followed accounts to a HashSet for O(1) lookups. Your own posts (is_self) are also in-network.
Why use a classifier? Phoenix (discovery) can sometimes return posts from followed accounts. The hydrator ensures that any post from a followed account gets in-network status, regardless of whether it came from Thunder (subscription) or Phoenix (discovery).
The boolean flag in_network propagates through the pipeline, affecting scoring and filtering. Separating classification from scoring allows independent evolution.
Stage 3: Pre-Filtering
Ten sequential filters prune the candidate pool before scoring to ensure quality and save computation.
DropDuplicatesFilter: Dedupes posts appearing in both Thunder and Phoenix.
CoreDataHydrationFilter: Drops incomplete candidates (missing ID/text).
AgeFilter: Enforces
MAX_POST_AGElimits.SelfTweetFilter: Excludes your own posts.
RetweetDeduplicationFilter: Resolves original vs. retweet duplications.
IneligibleSubscriptionFilter: Hides locked content from unsubscribed authors.
PreviouslySeenPostsFilter: Skips viewed posts (Bloom filters/IDs).
PreviouslyServedPostsFilter: Skips posts served in the current session.
MutedKeywordFilter: Enforces keyword mutes.
AuthorSocialgraphFilter: Enforces block and mute lists.
phoenix_candidate_pipeline.rs#L108-L120
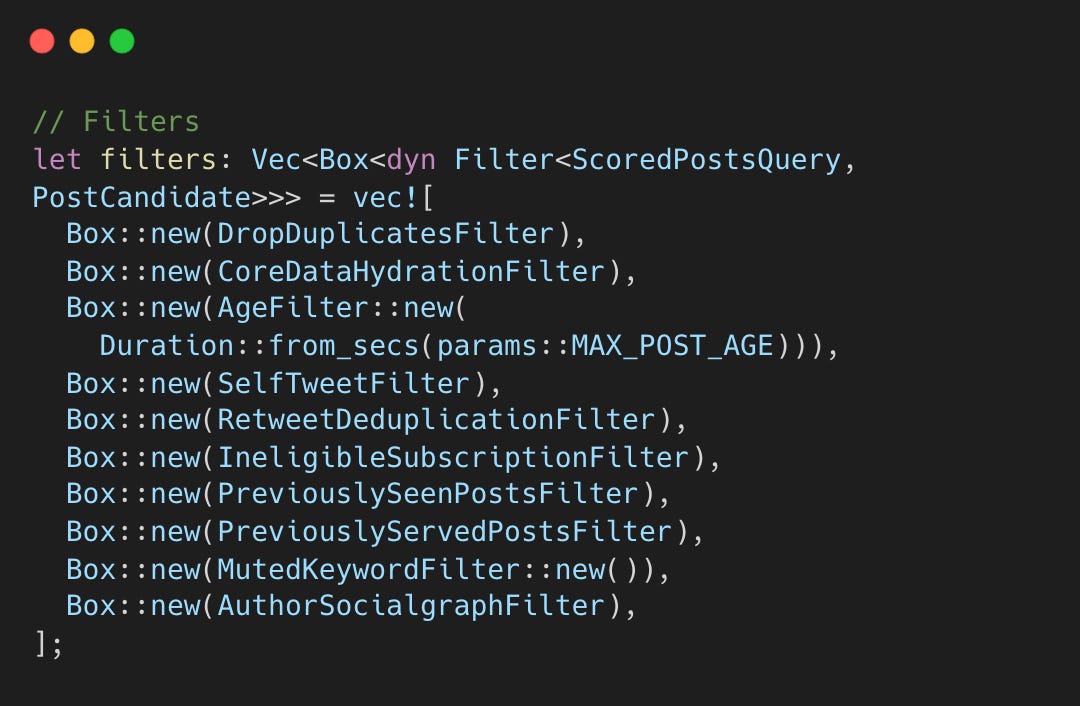
Only unique, fresh, eligible, and safe candidates proceed to scoring.
Stage 4: Scoring
This is where posts compete. Scoring happens in four sequential steps, defined in the pipeline configuration:
phoenix_candidate_pipeline.rs#L122-L132
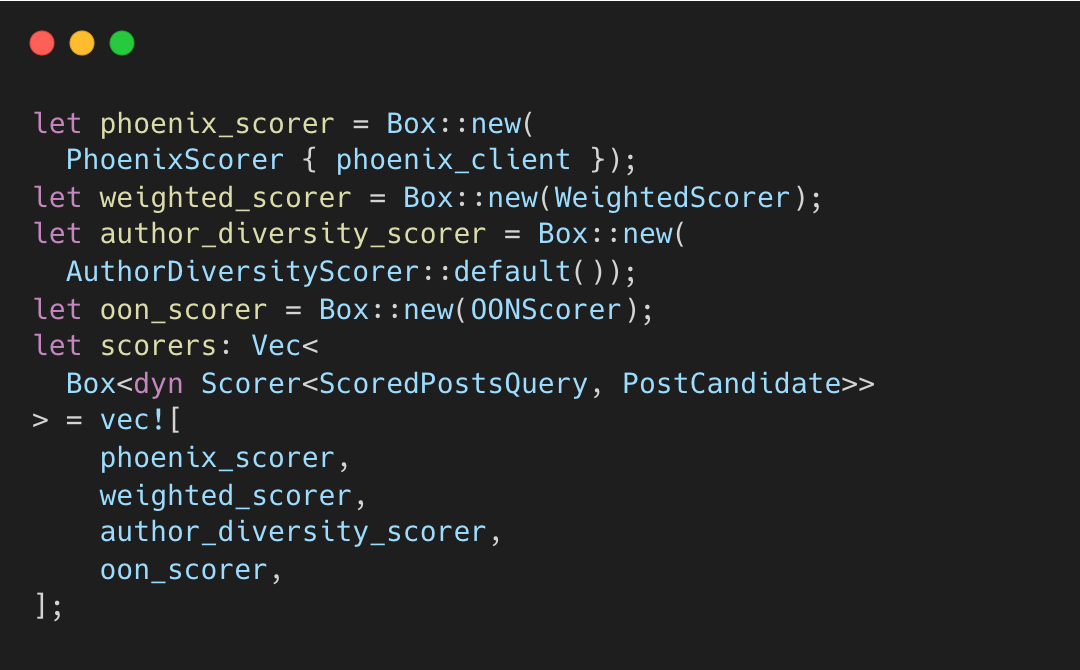
The order matters because each scorer depends on the previous output.
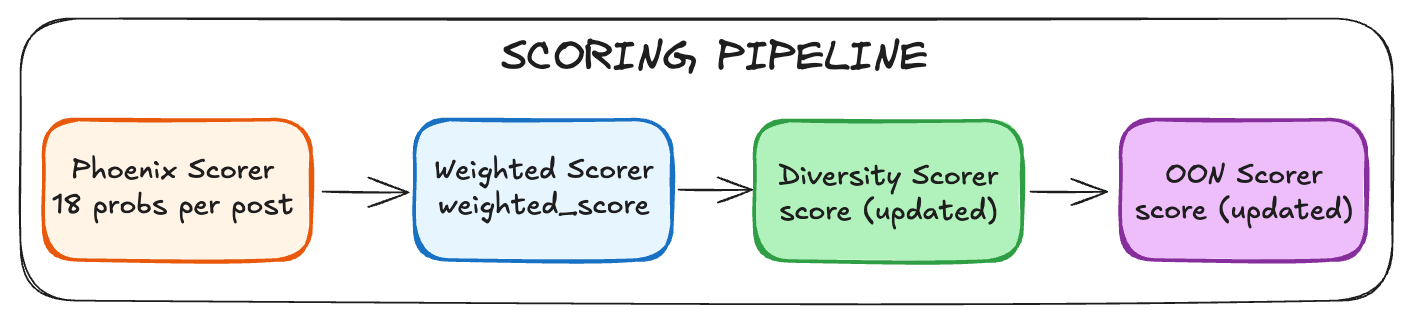
Step 4.1: Phoenix Transformer Predictions
Phoenix predicts 18 engagement probabilities and one continuous metric for each post.
Positive signals:
favorite_score: Probability you’ll likereply_score: Probability you’ll replyretweet_score: Probability you’ll repostphoto_expand_score: Probability you’ll expand a photoclick_score: Probability you’ll clickprofile_click_score: Probability you’ll visit author’s profilevqv_score: Video quality view (watching to completion)share_score,share_via_dm_score,share_via_copy_link_score: Sharing probabilitiesdwell_score: Probability you’ll stop scrollingquote_score: Probability you’ll quote tweetquoted_click_score: Probability you’ll click on a quoted tweetfollow_author_score: Probability you’ll follow after seeing
Negative signals:
not_interested_score: Probability you’ll click “Not interested”block_author_score: Probability you’ll blockmute_author_score: Probability you’ll mutereport_score: Probability you’ll report
Continuous metric:
dwell_time: Predicted time you’ll spend viewing the post
Phoenix scores all candidates in a single forward pass using a custom attention mask. But how do you batch candidates without their scores affecting each other?
Independent Scoring (Batch Independence)
Standard attention would allow candidates in the same batch to influence each other’s scores. To ensure a post’s score depends only on the user context, X uses make_recsys_attn_mask to isolate candidates.
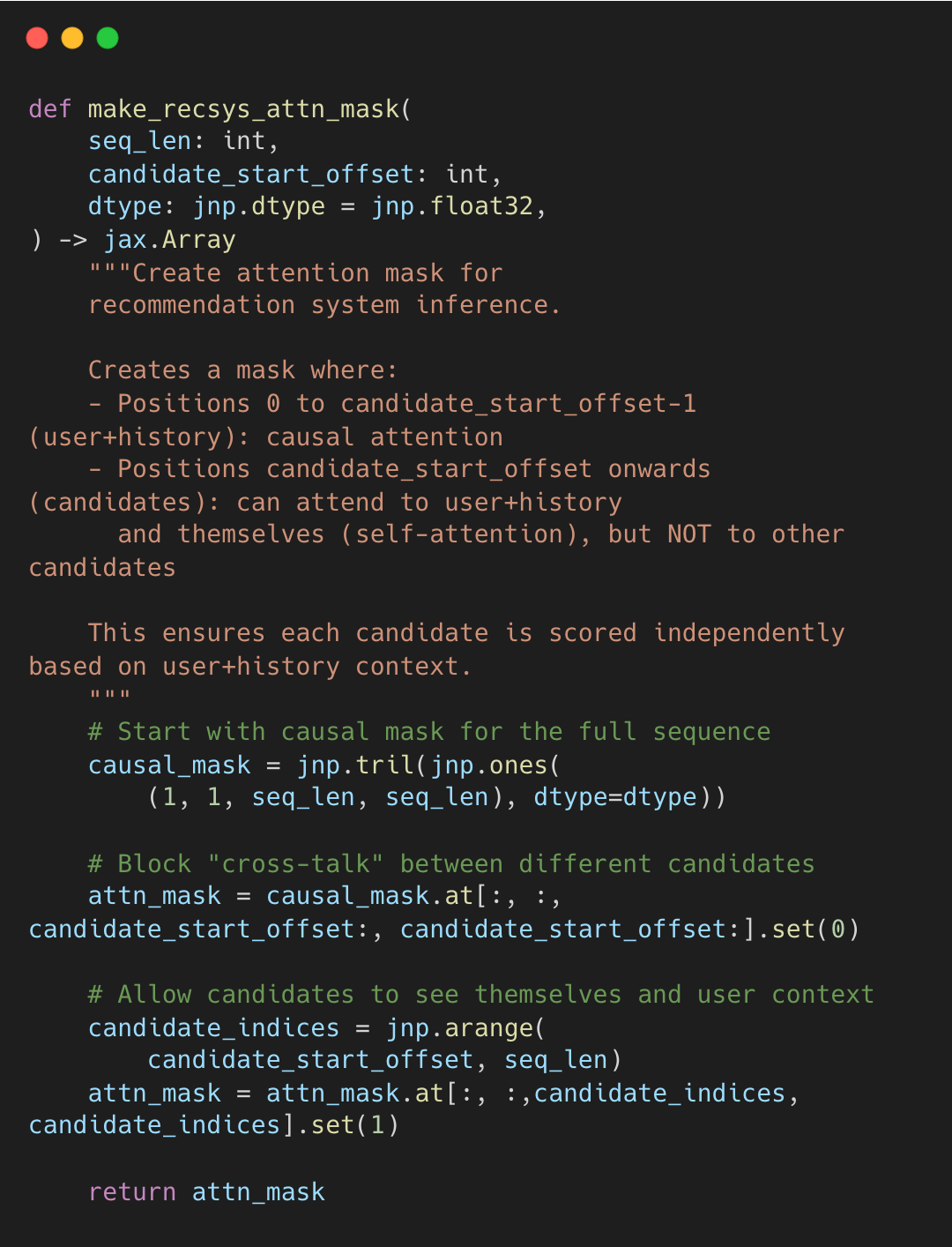
Each candidate attends to the user context and itself, but interaction with other candidates is blocked.
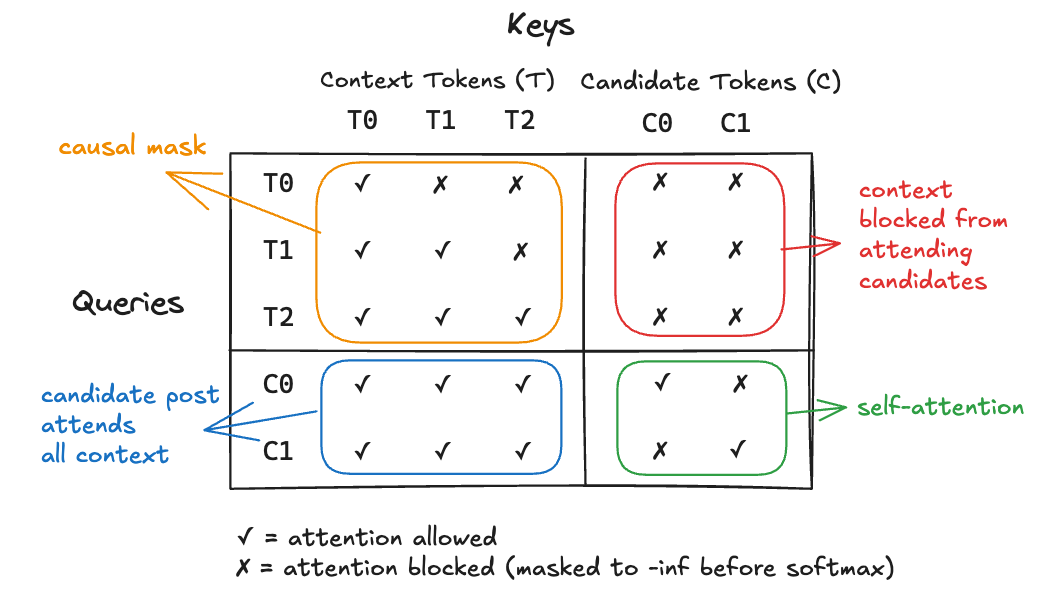
Each candidate gets the same score regardless of batch composition.
Step 4.2: Weighted Scoring
WeightedScorer combines the 18 probabilities and one metric into a single number:
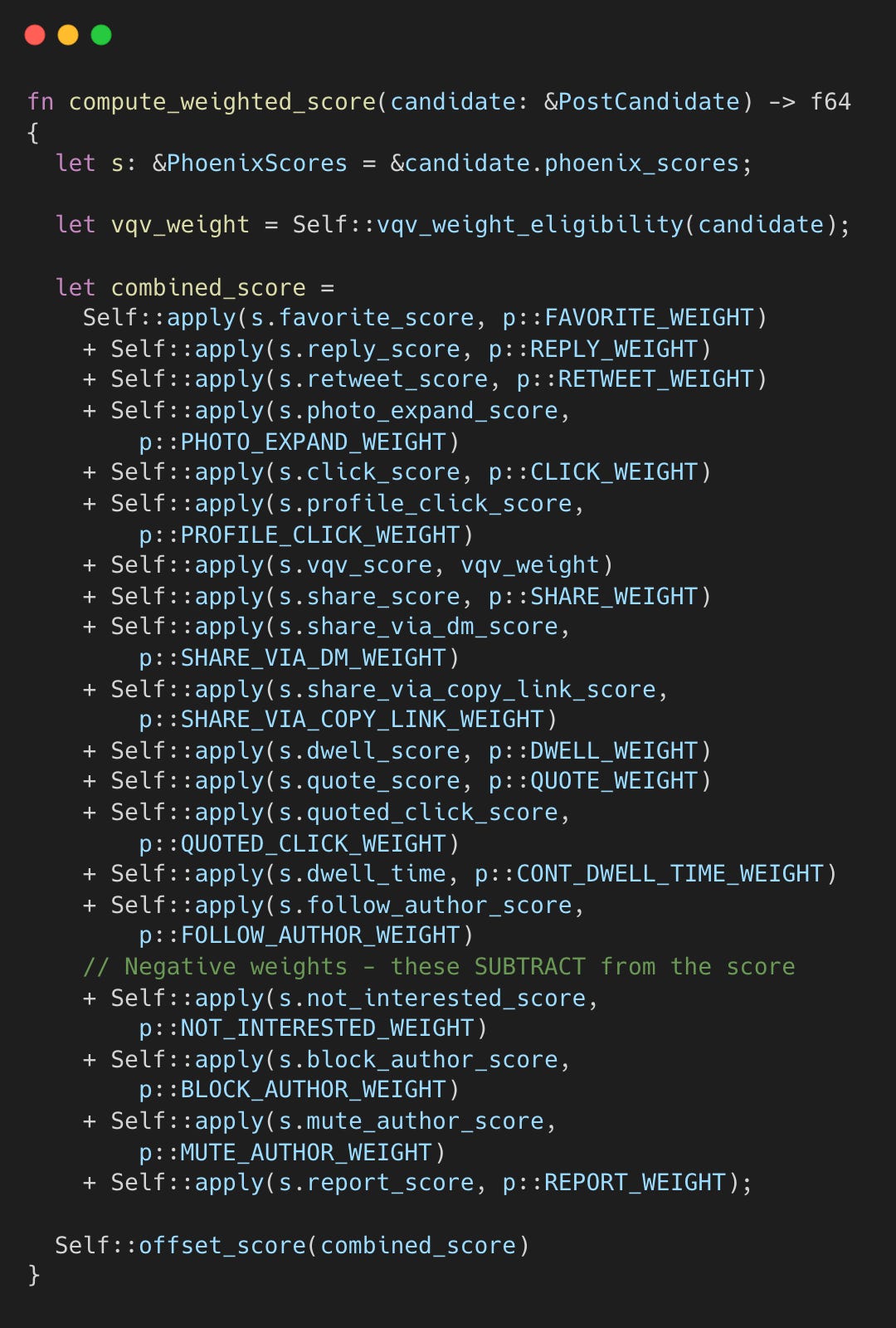
The last four weights are negative. Content that predicts blocking is penalized.
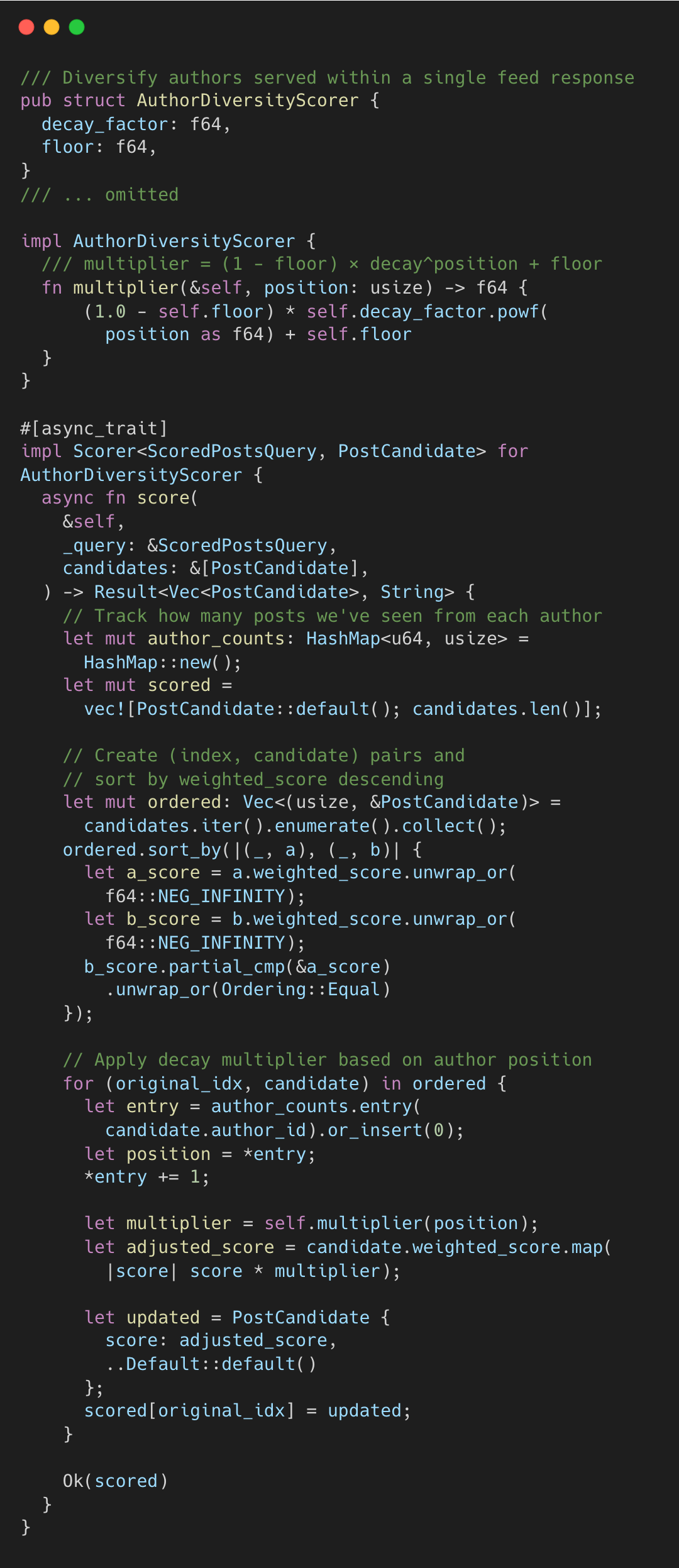
Step 4.3: Author Diversity—The Decay Function
To prevent one author from dominating your feed, X applies exponential decay.
author_diversity_scorer.rs#L10-L68
The decay curve is
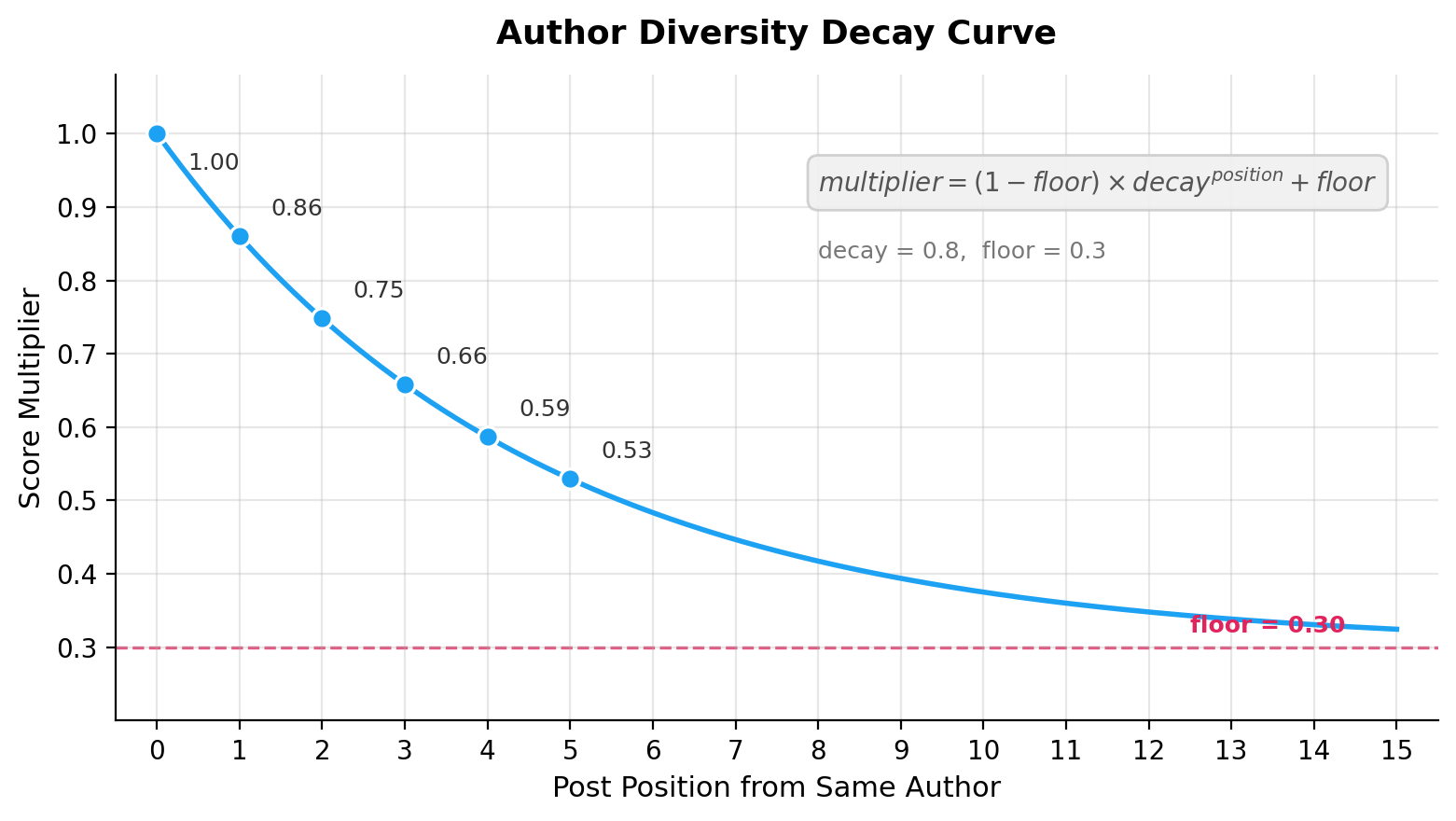
The floor parameter (e.g., 0.3) ensures even a prolific author’s later posts retain some score, balancing diversity with relevance.
Step 4.4: Out-of-Network Penalty
Finally, OONScorer penalizes posts from accounts you don’t follow.
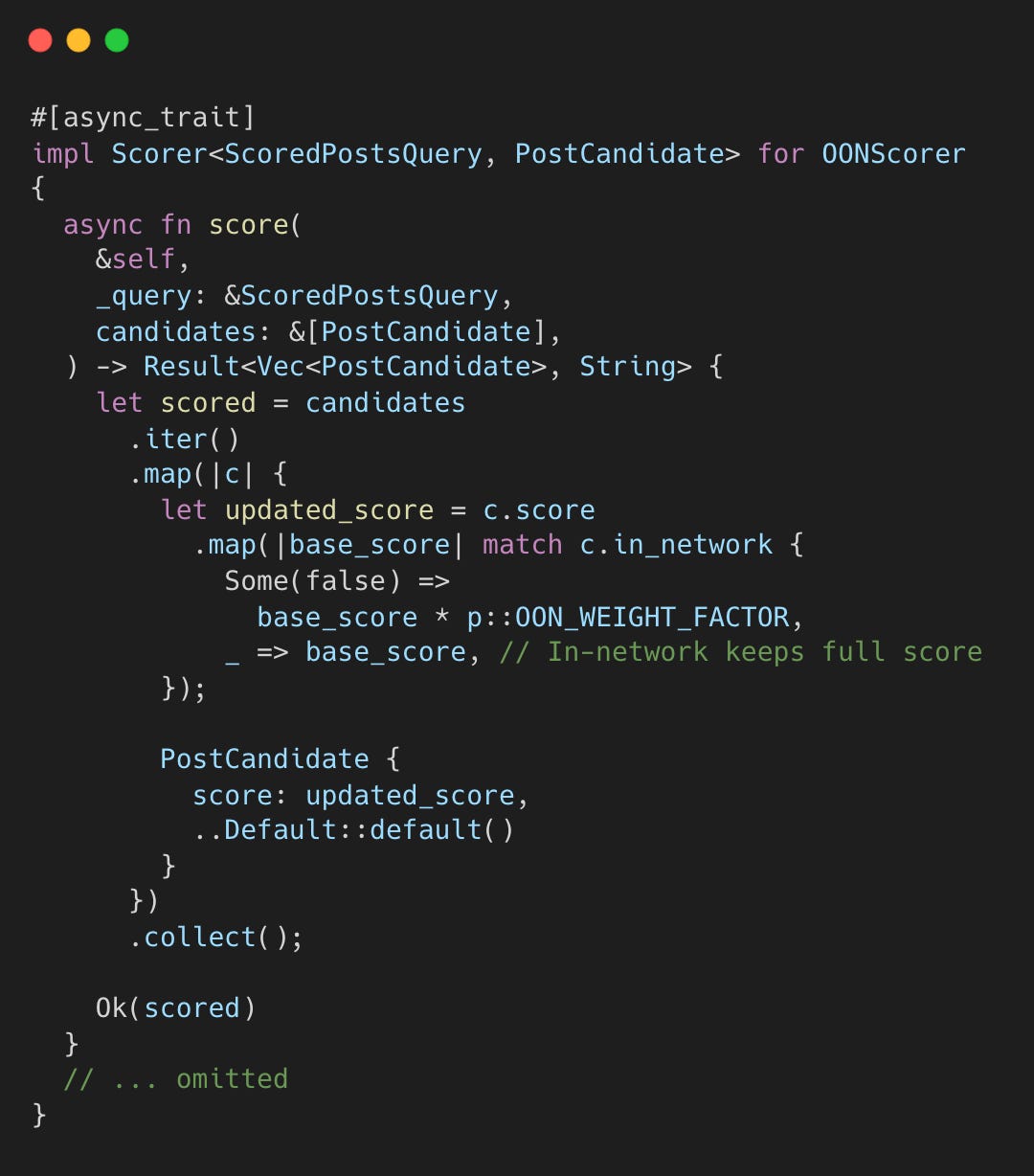
Posts from non-followed accounts are multiplied by OON_WEIGHT_FACTOR (e.g., 0.7), making them harder to rank high unless they are engaging.
Stage 5: Selection and Final Filtering
The TopKScoreSelector picks the top K candidates by score.
top_k_score_selector.rs#L6-L15
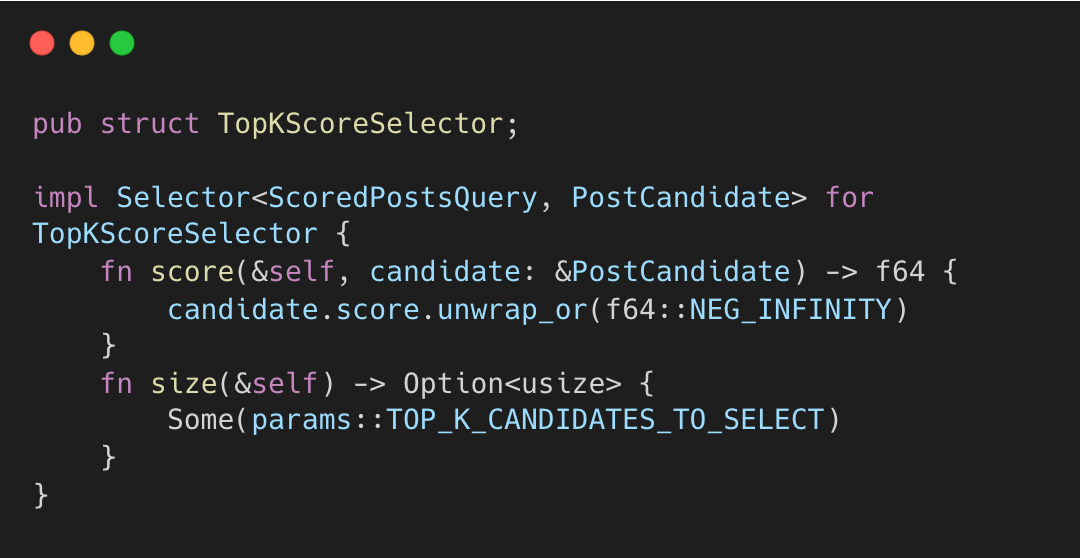
Results are sorted and truncated to size(). Before returning, post-selection hydration and filtering clean up the top set.
Visibility Filtering
Before the filter runs, VFCandidateHydrator queries an external visibility service. It applies different safety levels: TimelineHome for in-network posts, and the stricter TimelineHomeRecommendations for out-of-network posts. Both calls run in parallel.
VFFilter then drops any flagged candidate.
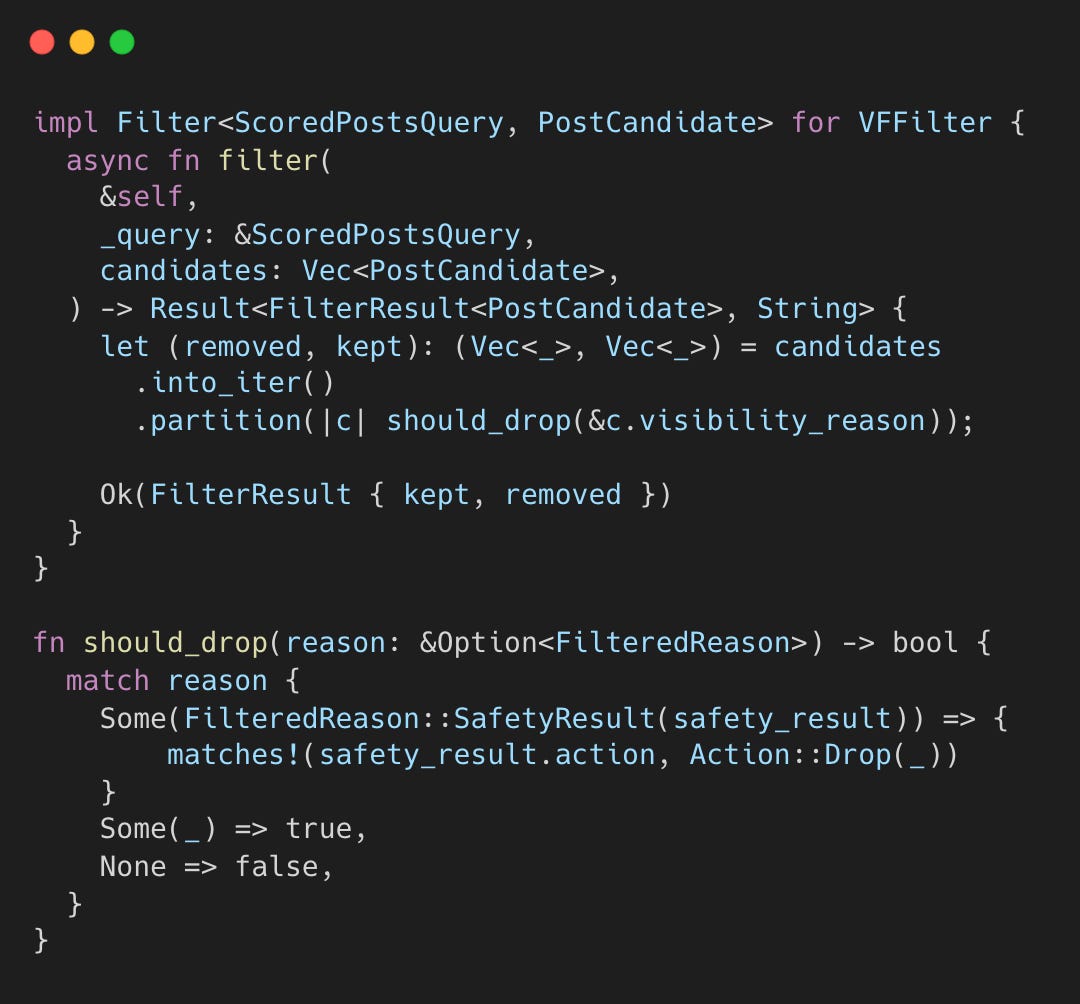
Any FilteredReason or Action::Drop triggers removal, leaving only posts with no visibility issues. The specific safety labels, like spam or policy violations, are determined by the external xai_visibility_filtering service.
Conversation Deduplication
DedupConversationFilter keeps only the highest-scored post per conversation thread:
dedup_conversation_filter.rs#L8-L51
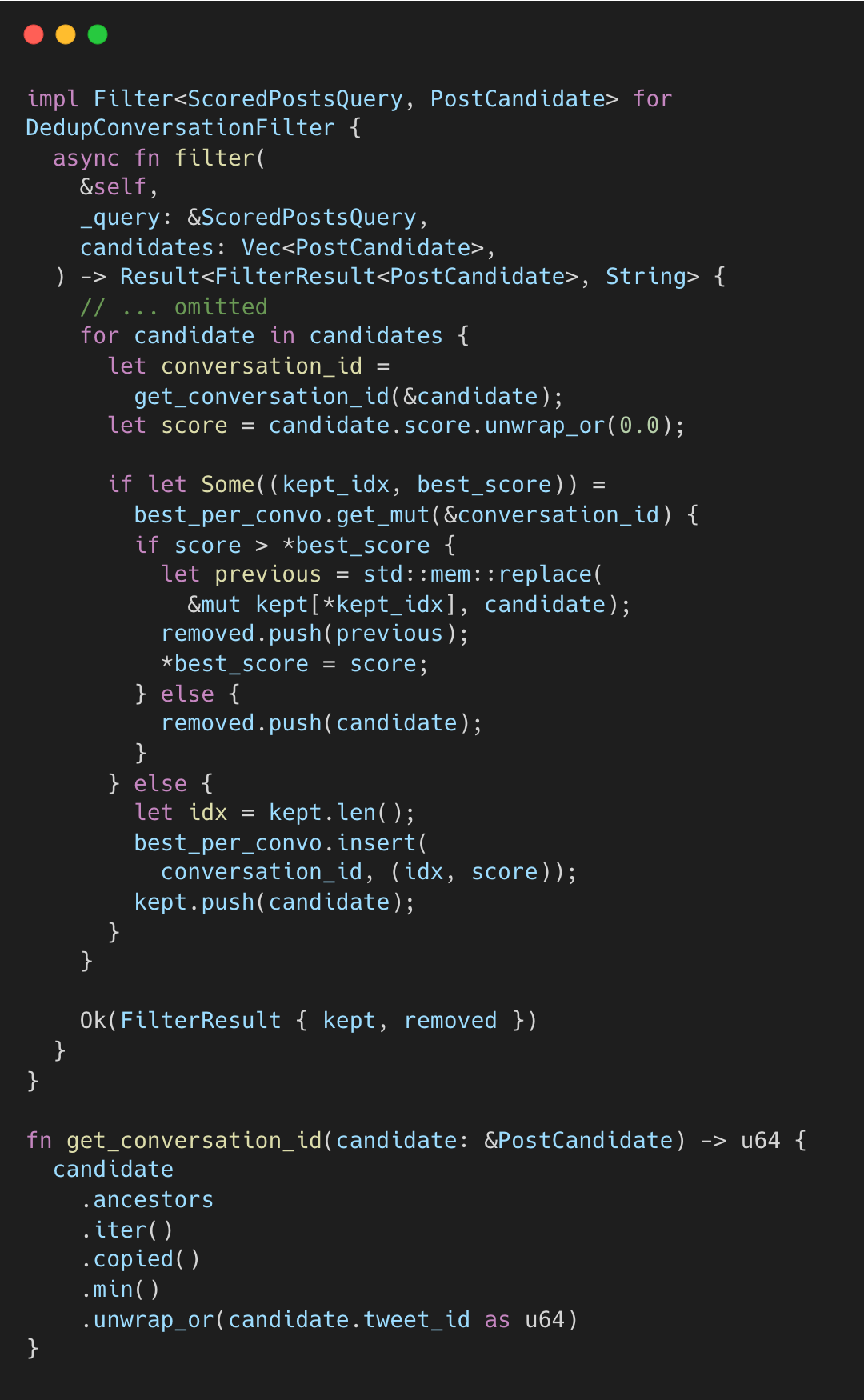
The conversation ID is the minimum ancestor ID, the root of the thread. If multiple posts from the same thread reach the top set, only the highest-scored survives. Standalone posts (no ancestors) use their own tweet_id, so they always pass.
The Complete Data Flow
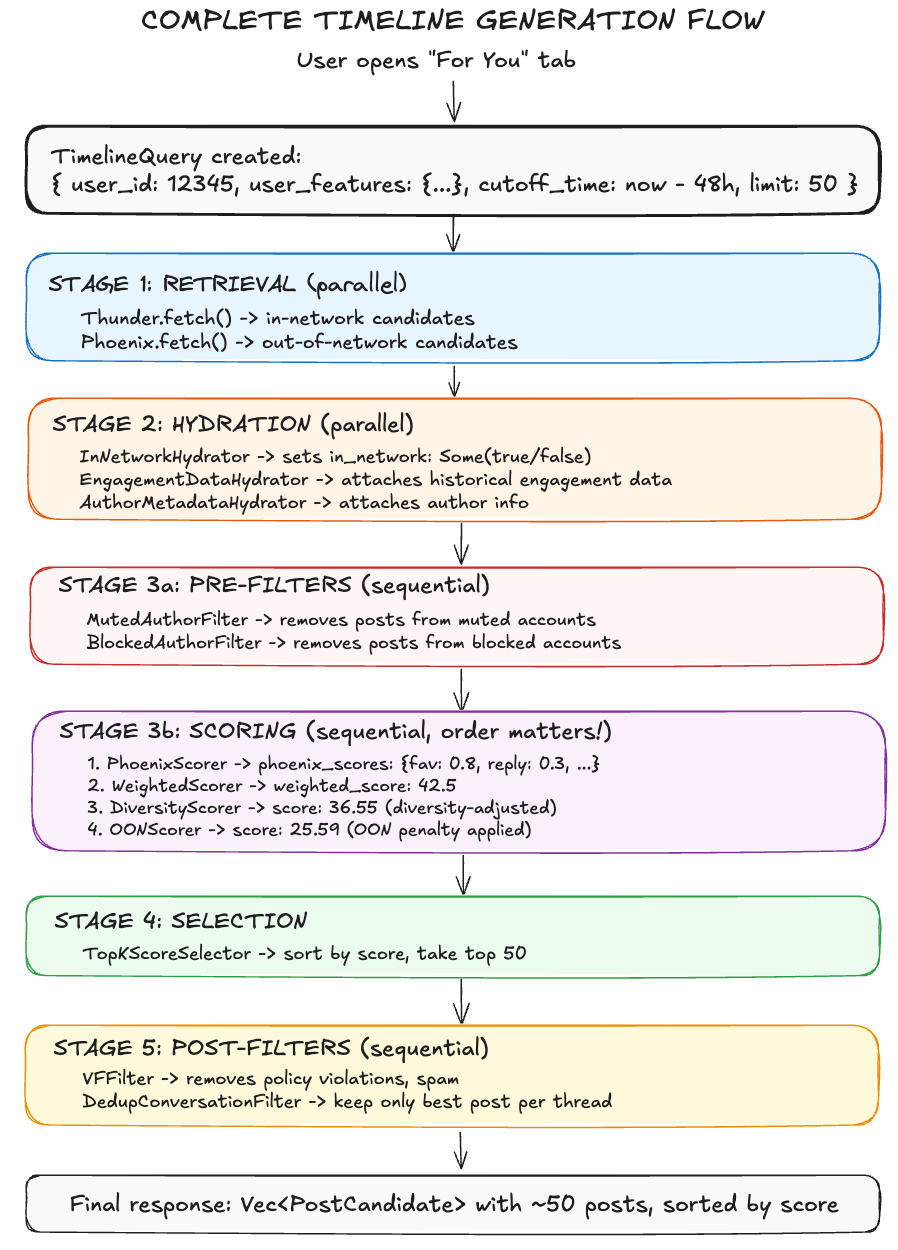
What This Means for Content Creators
The formula reveals what the algorithm values:
Maximize Positive Engagement: Likes, replies, shares, and video completion increase your score.
Minimize Negative Engagement: Blocks, mutes, and reports heavily penalize you.
Quality > Quantity: Exponential decay limits the reach of spamming.
Why does controversial content persist despite penalties?
Volume overwhelms penalty. A post with 10,000 likes and 100 blocks might score: 10,000×30 - 100×100 = 290,000 (using hypothetical weights). The sheer volume of positive engagement drowns out the penalty. Rage bait works when the engaged audience vastly outnumbers the offended minority.
User segmentation matters. Phoenix predicts per-user probabilities. If you historically engage with controversial content without blocking, the model predicts low block_author_score for you specifically. Rage bait isn’t shown to everyone, but it’s selectively served to users who tolerate it.
Quote-tweets count as positive. Angry quote-tweets trigger quote_score, which has a positive weight. Outrage sharing is still sharing in the algorithm’s eyes. The model can’t distinguish “quoting to criticize” from “quoting to endorse.”
Timing asymmetry. Early positive engagement triggers distribution. By the time blocks and reports accumulate, the post has already reached millions. The algorithm reacts to signals; it doesn’t predict future backlash.
Does the first hour matter?
There is no velocity scoring. No multiplier for “fast” likes.
Thunder (In-Network) fetches last 48h, sorted new-to-old. Recency is baked in.
Phoenix retrieve posts semantically. Older viral posts can surface if they match your interests, up to
AgeFilterlimits.
Early engagement still matters because of feedback loops.
Fresh Data: Phoenix re-scores with current stats on every request.
Compounding : More engagement → higher probability → more distribution → more engagement.
awesome stuff!
thanx